Unified C-programmable ASIP architecture for multi-standard Viterbi, Turbo and LDPC decoding
F. Naessens, P. Raghavan, L. Van der Perre, A. Dejonghe IMEC
Leuven, Belgium
Abstract:
This paper describes an ASIP decoder template suitable for multi-standard Viterbi, Turbo and LDPC decoding. We show architecture fitness for WLAN, WiMAX and 3GPPLTE standards, although various other standards can also be mapped, since the architecture is capable of supporting any interleaver pattern and programmable in C. The ASIP core consists out of a SIMD with multiple slots each with their dedicated functionality. Because of their block based approach and possible parallelization decoding strategy, both Turbo and LDPC were mapped using the same concept. Support for Viterbi decoding is made possible through a dedicated decoding pipeline with radix-4 to boost performance well above the tough throughput and latency requirements of the 802.11n standard. Specific instantiations are made to show the flexibility of the architecture. For each of these instances, area and throughput is given for a commercial 40nmG technology, showing to be competitive versus other flexible solutions, while offering some key differentiators in the sense of flexibility, usage and specific mode instantiation.
I. INTRODUCTION
Existing and emerging mobile communication networks are posing high requirements and flexibility, which paves the way for Software Defined Radio (SDR). A lot of advances were made in the inner modem processing [1][2][3][4], yielding to architectures that offer a high degree of parallel processing. The outer modem processing, more specifically in the channel decoding, is mainly dominated by dedicated ASIC solutions.
Recently some flexible implementation have been derived which support multi-standard channel decoding [5][6][7]. These solutions usually have a distinct pipelining for each of the decoding modes. With our solution we want to offer multi-standard decoding with maximum hardware re-use and full flexible memory allocation. Our previous solution offered support for flexible Turbo and LDPC decoding [8]. However we have further extended the architecture with extended functional support and enhanced throughputs while having a lower area footprint. Additionally there is a C-compiler with supports mapping functionality. Our solution proves to be flexible (both in supporting multi-standard LDPC, Turbo and LDPC as well as usage) and performant compared to State-of-the-art solutions [5][6][7].
The rest of the paper is structured as follows: Section II introduces the algorithms and how parallelization is exploited. In section III, the architecture is presented together with the instruction set and pipelining. Implementation results and benchmarking are detailed in sections IV and V respectively. Finally, section VI will conclude the paper.
II. DECODING ALGORITHM OVERVIEW
In contrary towards Viterbi decoding, low-densityparity- check (LDPC) and turbo codes are performing very close towards the Shannon limit. The main drawback however is their high computational complexity, which paves the way for parallel decoding architectures. In the next subsections all decoding modes will be detailed and specific focus will be given towards parallel decoding possibilities.
A. Viterbi decoding
Convolutional encoding is mandatory present in many communication standards. In a convolutional encoder, data bits are being fed into delay line, from which certain branches are xor-ed and fed to the output. If we consider WLAN as example, the throughput is being stressed towards decoder output rates of 600 Mbps (in IEEE 802.11n standard). Viterbi decoding is a near-optimal decoding of convolutional encoded data. It has a strongly reduced complexity and memory requirement compared to optimal decoding. It was introduced by Andrew J. Viterbi in his landmark paper [9].
During decoding, the most probably path is being determined based on the (soft) information bits and possible delay line state. Specifically in Viterbi, a window (with so called trace-back length) is considered before taking a decision on the most probable path and corresponding decoded bit. A high-level view on the decoding operation is depicted on Figure 1.
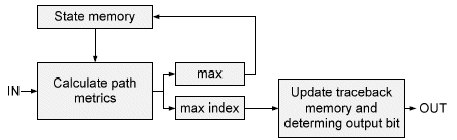
Figure 1 : Decoding overview
There is an iterative path regarding calculation of the state memory, which can be broken into parallel execution by applying a radix-2Z also called look-ahead factor Z [10]. In the remaining of this paper we will focus on a Viterbi decoder suited for WLAN operation, with polynomials equal to 133oct, 171oct. There is fixed decoding pipeline with dedicated registers for which a high level diagram is depicted on Figure 2. We have applied a look-ahead of factor 2 (also called radix-4 implementation), which could result in throughput performance equal to 2 output bits per clock cycle.
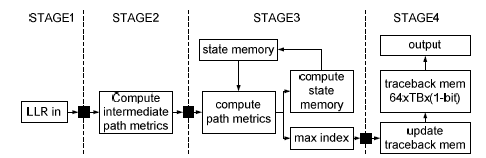
Figure 2 : Viterbi decoding pipeline
B. Turbo decoding
Decoding a turbo code requires iterating maximum a posteriori (MAP) decoding of the constituent codes and (de)interleaving operations. We have chosen to use the log-MAP with max* approximation. The parallelization of the log-MAP can be done either by augmenting the radix factor [11] or by computing in parallel multiple “windows” out of the coded block [12]. Figure 1 depicts the operation of a parallel log-MAP decoder with parallel windows. The top part (a) recalls the classical sliding windows log-MAP decoding flow. A forward recursion, given by (1) is applied to the input symbol metrics (g). Part of the backward recursion (2) is started after a window of M inputs is treated by the forward recursion. The recursion is then initialized either using a training sequence applied on the symbol metrics from the adjacent window, or using backward state metrics (b) from a previous iteration (next iteration initialization, NII). Based on the state metrics output of the forward (a) and backward (b) recursions, next to the input symbol metrics (g), the log-MAP outputs (extrinsic information, e) can be computed. Using NII is preferred as it leads to more regular data flow. That way, as shown in the bottom part of the figure (b), the log-MAP decoding can easily be parallelized by computing several windows in parallel.

Figure 3 : Parallel log-MAP decoder
Besides the log-MAP, interleaving operations must also be parallelized. As interleaving means intrinsically permutation the data out of a memory, parallelizing it requires to use multiple memory banks and handle potential collision in read and write operations. For this, collision free interleaving patterns or collision-resolution architectures were proposed in [13] and [14] respectively. Later, Tarable proved in [15] that any interleaving law can be mapped onto any parallel multi-banked architecture. He also proposed an annealing algorithm that is proven to always converge to a valid mapping function.
In this work, we are capitalizing on the multi-window log-MAP parallelization combined with Tarable’s interleaving law mapping. Contrarily as what we did in [12] however, we do not parallelize the forward and backward recursion anymore. This is to enable single instruction multiple data (SIMD) implementation of the datapath. If SIMD is used to parallelize multiple windows, a restriction is that the same operation has to be applied to all the parallelized windows at the same time. With our original parallelization [12], each “worker” (structure implementing two adjacent windows) had to operate forward and backward steps in parallel, which is impossible in SIMD. Also, for the same reason, the computation of gs, as and bs over the branches or states are serialized.
C. LDPC decoding
When considering a (n,k) LDPC code, with k information bits and n coded bits the parity check matrix H is of dimension [(n-k) × n]. Simulations have shown that the layered decoding reduces the number of iterations needed to converge [16][17]. In layered decoding [18] the parity check matrix needs to be decomposable into m sub-matrices with size [z×n], also called super-codes as depicted on Figure 2. For every super-code, the position of 1s is restricted such that, per column in a super-code, only zero or one non-zero element is allowed. For the standards in scope this property is either automatically met, through the fact that the sub-matrices within the super-codes are either zero matrices or cyclic permuted identity matrices, or can be derived.
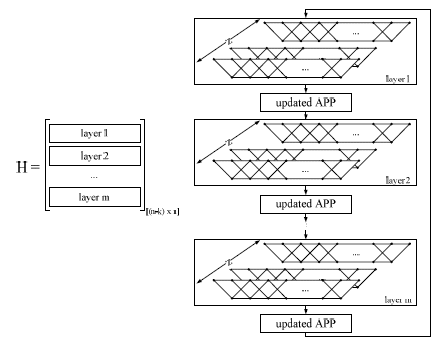
Figure 4 : LDPC Layered Decoding
Due to the latter property, within a layer, the check node updates and corresponding bit node updates can be done in parallel since there is only one edge from every bit node towards a check node in a layer. Intrinsically this enables z parallel processing threads each performing check node updates and message node updates corresponding to a row within the layer of the parity check matrix. An overview of the possible z values within the standards in scope is summarized in Table 1. In order to achieve the best BER performance, the turbodecoder- based approach, with the max* [16] approximation is favored. Within the z parallel processing threads, the calculation of the forward and backward recursion metrics as well as the bit node update messages can be calculated.

Table 1 : z-value Within Standards in Scope
III. ARCHITECTURE OVERVIEW
Based on the parallelization intrinsically present in the algorithms detailed in section II, a SIMD implementation covers the constraints. An overview of the architecture is depicted on Figure 5.
The architecture exists out of a SIMD engine connected to scalar data memory and two (local) vector memories. In order to comply with all permutation and interleaving patterns, the background memory is connected through a crossbar. Both the address and the crossbar control are configured through lookup table which is driving by a virtual address.
The SIMD engine was developed using Target tool suite [19], offering next to high level modeling of processor resources also a C-compiler to efficiently explore and map the decoding applications. There are six parallel slots for which the first one is operating on scalar field only and mainly used for initialization and loop control. The processor has following properties:
- instruction width of 80 bits
- scalar word width of 12 bits (signed)
- vector word width of 8 bits (signed)
- 16 scalar registers
- 8 vector registers
- Maximum pipeline depth of 8 (only utilized for loads from background vector memory)
- Stack implemented on DM and VMEM memory
The instruction set is depicted on Table 2. The instruction set is quite limited and still offers support for most of the C-code constructs.
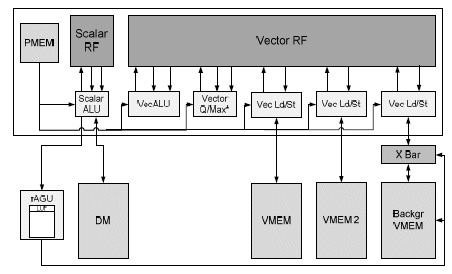
Figure 5 : Architecture overview
Table 2 : Instruction set overview
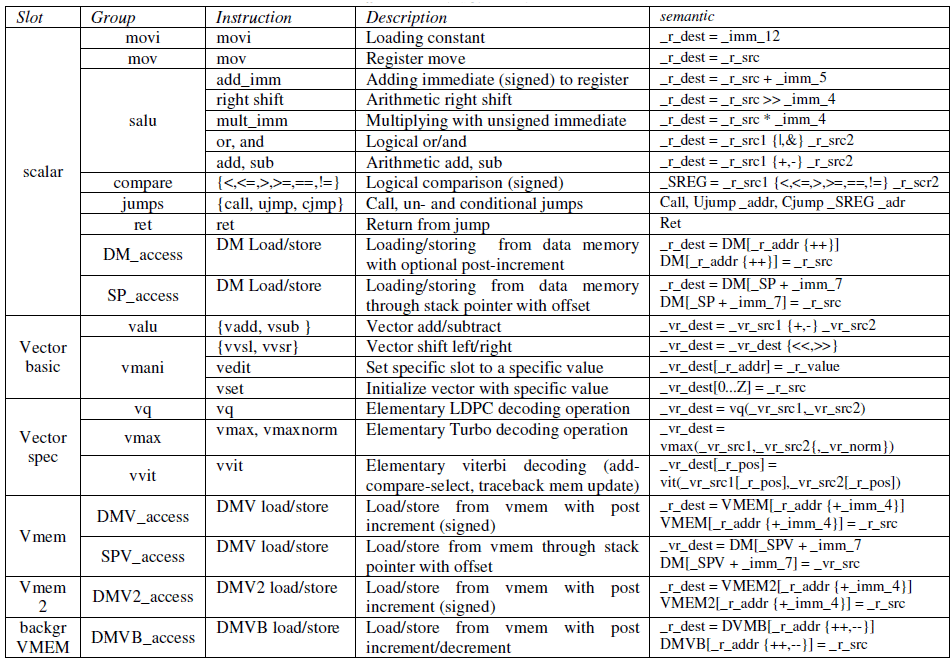
An example of a firmware kernel and it corresponding assembly can be found in Table 3 and Table 4. The code is part of the LDPC decoding which decodes a layer existing out of 6 non-zero parity check sub-matrices. The loops are automatically unrolled (through compiler directives) and mapped onto 29 cycles.

Table 3 : Firmware C-code example
The slot utilization for the different processing kernels is depicted on Figure 4. One can clearly observe that the viterbi decoding kernel doesn’t utilize the vector alu and local vector memory slots. In overall, a quite dense schedule is achieved, certainly taking into account the very limited number of vector registers. Increasing the number of vector registers would be beneficial for the schedule, but would drastically increase the occupied area and power consumption of the SIMD processing core.
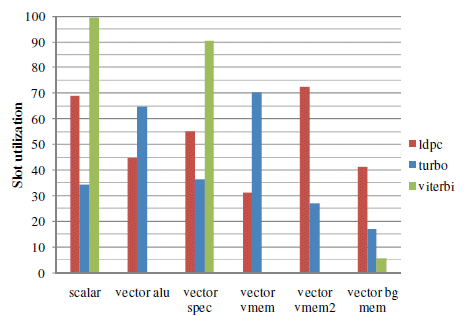
Figure 6 : Slot utilization [%] for the different processing kernels (turbo, ldpc, viterbi)
Table 4 : Resulting assembly code mapped over different ASIP core slots

IV. IMPLEMENTATION RESULTS
A. Template instantiation
Based on the requirements of the decoding modes a parallelization of 96 slots is selected. We considered three distinct instances for which the supporting modes are summarized in Table 5. In order to allow a comparison, internal quantization was fixed towards 8 bit for all instantiations.
Table 5 : Distinct instantiations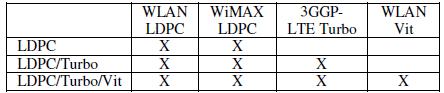
The mapping onto the memory hierarchy for each of the decoding modes is depicted on Figure 7. Since the Viterbi decoding has a dedicated pipeline, there is no need for usage of the local vector memory. The memory requirements are clearly driven by the Turbo decoding mode.

Figure 5 : Variable mapping onto memory hierarchy for different deocoding modes
An overview of the implementation details for each of the instances is given in Table 6. In case of the LDPC only instance, considerable amount of complexity can be avoided. First the number of scalar and vector registers can be reduced significantly without sacrificing throughput performance; secondly the full crossbar can be replaced by a rotation engine (barrel shifter) due to the properties inside the WLAN and WiMAX LDPC codes. On top of that the memory requirements are much lower and the background memory doesn’t need to be segmented separately over the 96-slots.
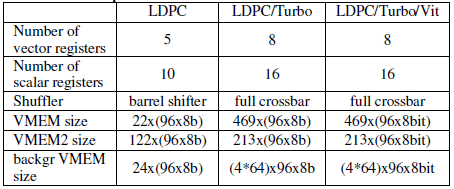
Table 6 : implementation details for different instances
B. Area
For the implementation, a 0.9V 40nm process was selected. Logic synthesis was performed using commercial tools and a floorplan utilization of 60% was taken into account. Memory area is based on macros of commercial available memory IP vendor. In Figure 6 you can find the area for the ASIP core for each of the template instantiations, which clearly shows the high area impact of the vector registers and the overhead of Viterbi decoding as completely independent pipeline (contribution both in ‘alu vector spec’ as in ‘other regs’). The overall area for each of the instances can be found in Table 7, which clearly shows the architecture is memory dominated and for this memory constraints, the 3PP-LTE Turbo decoding mode is the most demanding one.
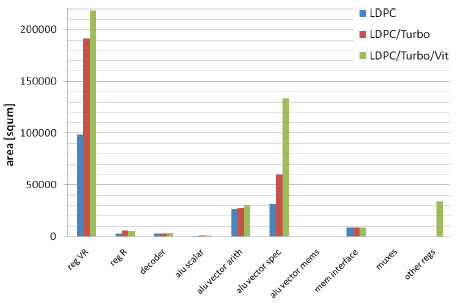
Figure 8 : ASIP area distribution for different instances
Table 7 : Overall area overview for different instances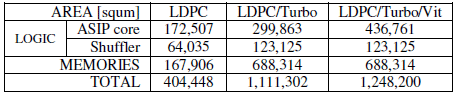
C. Throughput
An overview of some of the throughputs which can be achieved are shown in Table 8. As for the Viterbi decoding, the throughput is approaching a two output bits per clock cycle. The overhead is coming from the memory access and loop control
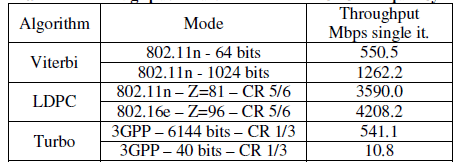
Table 8 : Throughput results for 800MHz clock frequency
D. Power/energy efficiency
An overview of the power consumption and according decoding energy efficiency is depicted on Figure 9 and Figure 10 respectively. The leakage is relatively small compared to the dynamic power consumption. The power consumption (hence also energy efficiency) is slightly increasing from the LDPC only instance compared to the full flexible solution.
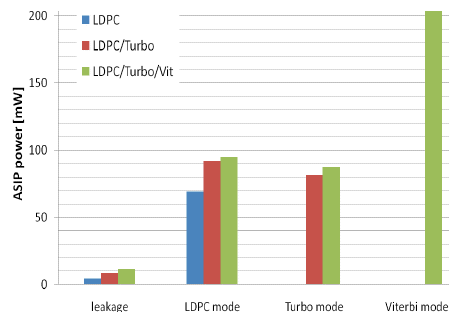
Figure 9 : ASIP power consumption
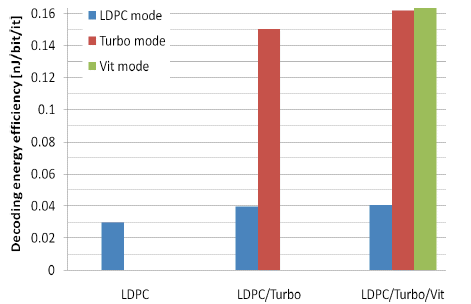
Figure 10 : Decoding efficiency for different modes mapped onto different instances
V. COMPARISON VERSUS STATE-OF-THE-ART
Comparison of our solution versus other flexible solutions is shown on Figure 11. All solutions were compared with a throughput over logic-area metric, were area numbers were scaled towards 40nm technology. Our solution show to be very competitive versus other solutions and further tuning is possible when removing the Viterbi and/or Turbo decoding mode support. On top of that we offer a high degree of flexibility through support of any interleaver pattern and C-programmable core. In addition, some of the proposed solutions [5][6] will not be able to meet the demanding latency and throughput constraints posed by the WLAN standard.
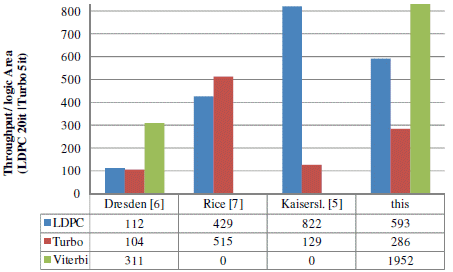
Figure 11 : Flexible multi-standard comparison (based on throughput/logic-area ratio)
VI. CONCLUSIONS
We have shown a flexible architecture which can be seen as a template suited for multi-standard multi-mode LDPC, Turbo and Viterbi decoding. Both LDPC and Turbo can be nicely parallelized to be mapped onto a SIMD engine. In order to boost the throughput, the SIMD engine consists out of parallel slots, each with their dedicated functionality. Viterbi support is enabled through a dedicated pipeline for which we have selected a radix-4 for enhanced throughput.
Some specific instantiations of the template have been implemented in a commercial 40nmG technology and show to be competitive versus other state-of-the-art solutions, while offering clear benefits in flexibility, usage and specific mode instantiation.
REFERENCES
[1] B. Bougard et al., “Energy Efficient Software Defined Radio Solutions for MIMO-based Broadband Communication”, Proc. European Signal Processing Conference, Sept. 2007”
[2] B. Bougard et al., “A Coarse-Grained Array based Baseband Processor for 100Mbps+ Software Defined Radio”, Design Automation and Test in Europe, March 2008
[3] J. Glossner et al., “The Sandblaster SB3011 platform”, EURASIP Journal on Embedded Systems, 2007
[4] Yuan Lee et al., “SODA: A High-Performance DSP Architecture for Software-Defined Radio”, IEEE Micro, 2007
[5] Alles M, Vogt T, Wehn N. FlexiChaP: A reconfigurable ASIP for convolutional, turbo, and LDPC code decoding. 2008 5th International Symposium on Turbo Codes and Related Topics.
[6] Kunze S, Matuˇ E, Corp NEC. A ” Multi-User ” approach towards a channel decoder for convolutional, Turbo and LDPC codes, TU Dresden Vodafone Chair Mobile Comm . Systems System IP core research labs. Architecture. 2010:390-395.
[7] Sun Y, Cavallaro JR. A Flexible LDPC/Turbo Decoder Architecture. Journal of Signal Processing Systems. 2010;(November 2009).
[8] Naessens F, Derudder V, Cappelle H, et al. and decoder for 802 . 11n , 802 . 16e and 3GPP-LTE. VLSI symposium. 2010:213-214
[9] Andrew J. Viterbi, ”Error bounds for convolutional codes and an asymptotically optimum decoding algorithm”, IEEE Transactions on Information Theory 13(2):260–269, April 1967
[10] G. Fettweis and H. Meyr, “High-Speed Parallel Viterbi Decoding: Algorithm and VLSI-Architecture“, IEEE Comm. Magazine, May 1991.
[11] M Bickerstaff et al., “A 24Mb/s radix-4 logMAP turbo decoder for 3GPP-HSDPA mobile wireless”, ISSCC, Feb 2003
[12] B. Bougard et al., “A scalable 8.7 nJ/bit 75.6 Mb/s parallel concatenated convolutional (turbo-) CODEC”, ISSCC, Feb. 2003
[13] Giulietti, A.; van der Perre, L.; Strum, A., "Parallel turbo coding interleavers: avoiding collisions in accesses to storage elements," Electronics Letters , vol.38, no.5, pp.232-234, 28 Feb 2002
[14] Thul, M.J et al, "A scalable system architecture for highthroughput turbo-decoders," IEEE Workshop on Signal Processing Systems, 2002, pp. 152-158
[15] Tarable, A.; Benedetto, S.; Montorsi, G., "Mapping interleaving laws to parallel turbo and LDPC decoder architectures", IEEE Transactions on Information Theory, vol.50, no.9, pp. 2002-2009, Sept. 2004
[16] M. Mansour and N. Shabhag, “High-throughput LDPC decoders”, IEEE Trans. VLSI Syst., 11(6): pages 976-996, Dec 2003 [17] R. Priewasser, M. Huemer, B. Bougard, “Trade-off analysis of decoding algorithms and architectures for multi-standard LDPC decoder”, IEEE Workshop on Signal Processing Systems, 2008.
[18] D. Hocevar, “A Reduced Complexity Decoder Architecture via Layered Decoding of LDPC Codes”, IEEE Workshop on Signal Processing Systems, 2004, pages 107-112.
[19] Target Compiler Technologies, http://www.retarget.com/
Related Semiconductor IP
- Ultra-Low-Power LPDDR3/LPDDR2/DDR3L Combo Subsystem
- 1G BASE-T Ethernet Verification IP
- Network-on-Chip (NoC)
- Microsecond Channel (MSC/MSC-Plus) Controller
- 12-bit, 400 MSPS SAR ADC - TSMC 12nm FFC
Related Articles
- A Low Complexity Parallel Architecture of Turbo Decoder Based on QPP Interleaver for 3GPP-LTE/LTE-A
- From a Lossless (~1.5:1) Compression Algorithm for Llama2 7B Weights to Variable Precision, Variable Range, Compressed Numeric Data Types for CNNs and LLMs
- Functional Safety for Control and Status Registers
- Procrastination Is All You Need: Exponent Indexed Accumulators for Floating Point, Posits and Logarithmic Numbers
Latest Articles
- Extending and Accelerating Inner Product Masking with Fault Detection via Instruction Set Extension
- ioPUF+: A PUF Based on I/O Pull-Up/Down Resistors for Secret Key Generation in IoT Nodes
- In-Situ Encryption of Single-Transistor Nonvolatile Memories without Density Loss
- David vs. Goliath: Can Small Models Win Big with Agentic AI in Hardware Design?
- RoMe: Row Granularity Access Memory System for Large Language Models