OCP Interface for SoC - Verifying the Implementation of Embedded Processors
By Yasumasa Nakada, Chief Specialist, IP Development Group and Masataka Matsui, Senior Manager, SoC Research & Development Center, Toshiba Corporation Semiconductor Company
Courtesy of OCP-IP
Adopting OCP for in-house SoCs
Toshiba Semiconductor Company decided to widely adopt OCP as the host interface for in-house IP cores. OCP, which is standardized by OCP-IP, is the specification standard host interface for these cores (figure 1). Differing from existing host interfaces, in which each signal line is shared by several IPs, OCP defines the channel method by securing an effectual data transfer rate. In order to establish a design methodology that could change existing IP cores into an OCP-compliance core, the MeP host interface (the processor core for motion picture products, etc.) was changed into OCP to produce a sample SoC MeP core. MeP includes features which allow the size of the cache memory and local RAM to be changed, the ability to change the number of channels and level for interruption, and the variation of time and counter features. MeP can also be used with DSP and hardware engines (figure 2).
In the sample SoC, multiple MeP functions were used for video processing, audio processing etc. Each module is connected to others by the interconnect bus called, “MeP bus”.

Figure 1. The concept of OCP

Figure 2. The structure of MeP module
Reducing the development cost by using a general interface
The MeP bus includes a protocol from the Toshiba original specification. As a result, when the design of the modules connected to the MeP bus are changed, a re-evaluation of the whole SoC needs to be done in order to determine if the MeP bus satisfies the required performance. These re-evaluations can sometimes cause delays in the development period. By replacing the connection between the modules with OCP, the development and modification work for each module is reduced (figure 3). As a result, there are four requirements for the new host interface: (1) it must be an open standard protocol, (2) it cannot depend on any existing bus protocol, (3) it must be a configurable specification (depending on the required performance) (4) it must be an evolving standard. It is important that the protocol be an open standard in order to accommodate the procurement or licensing of an interconnect IP core from an IP vendor, such as a bus IP or cross-bar switch IP.
Although it was possible to use other industry standard specifications for the on-chip bus protocol, OCP was adopted because it is the only interface specification that does not depend on any data transmission protocol tied to CPU cores or buses. For this reason, OCP is the most suitable bus protocol for use in SoC design.
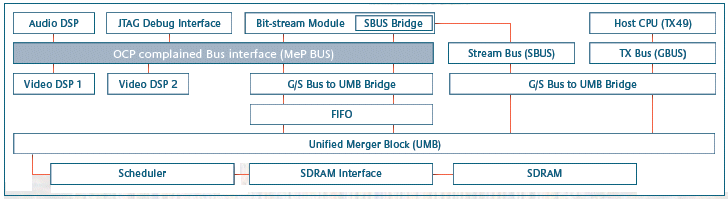
Figure 3. The structure of the sample SoC
Defining the specification using “Taguchi methods”
OCP defines various functions, but the mandatory interface specification set by OCP is moderate. When designing a SoC with OCP-compliant host interface IP, a designer defines the detailed specification by considering the performance and cost of the SoC. The first step in converting the MeP host interface into OCP was to define the performance parameters.
Securing bandwidth for the CPU
Initially, the priority conditions were listed: for example, 130-150MByte/sec bandwidth for the bus between the CPU core and synchronous DRAM at the peak. Synchronous DRAM is shared by the CPU core and each module of the SoC. When the access for synchronous DRAM from each module increases, access to DRAM from the CPU core is delayed. Since the CPU core controls the entire SoC, the operation delay also influences the entire SoC. When the OCP parameters were configured, the bandwidth was reserved by the max load assumption in order to avoid the delay of the CPU core operation at the peak. Additionally, the necessary bandwidths for each module were defined, which deferred any peak bottlenecks. To determine the simulation performance with the Taguchi methods, 12 evaluation properties were prepared (table 1). In accordance with these requirements, the most appropriate specification was defined. After this, the assignment of OCP threads was decided. In the OCP specification, if the data transmissions use the same thread, the order of the load and store is maintained. This condition implies that the exclusive access control and bus utilization rate will come down. As a result, separate threads are used for transactions which can be transmitted out-of-order.
| Usage | Evaluation property | Measurement or computation method | Required condition |
| Assign the data processing amount suitable for each module | Processing performance of the Video DSP1 | Measure the number of 1MByte data processing cycles and evaluate the data processing amount by computing the inverse | Not exceed 200MIPS (Max frequency is 200MHz) |
| Processing performance of the Video DSP2 | |||
| Adjust the bandwidth of the data transfer through the MeP bus | DMA transfer latency of the Audio DSP | Operation cycle of the DMA transfers | Minimize as far as possible |
| DMA transfer latency of the Bit-stream Module | |||
| DMA transfer latency between the Graphics module and the MeP bus | The number of necessary cycles required to read the one line graphic data from the synchronous DRAM | Should be less than the maximum, so as not to distort the graphic | |
| DMA transfer latency between the Graphics module and the UMB | The number of data transfer cycles between the graphics module and the synchronous DRAM | ||
| Data transfer latency of the Video capture module [1st] | At the time of graphic data transfer from the synchronous DRAM the video capture module, which is included in the graphics module, transfers the one line graphic data by dividing three times | ||
| Data transfer latency of the Video capture module [2nd] | |||
| Data transfer latency of the Video capture module [3rd] | |||
| Secure the necessary minimum bandwidth to transfer the specific data | Maximum bandwidth for the Graphics module | The maximum bandwidth of the DMA data transfer from the graphics module to the synchronous DRAM | More than 300MByte/sec |
| Maximum bandwidth for the Host CPU | The maximum bandwidth of data transfer from the Host CPU to the synchronous DRAM | 130MByte/sec - 150MByte/sec, or greater | |
| Maximum bandwidth for the Bit-stream Module | The maximum bandwidth of data transfer through the stream bus from the Bit-stream Module to the synchronous DRAM | More than 100MByte/sec |
Table 1. 12 evaluation properties
Managing performance assurance and shortening the development period
Simulations based on Taguchi methods were repeated and OCP parameter configuration specification was defined by adopting the best simulation result. As the SoC scale became larger, the number of modules embedded and the number of buses increased. As performance is refined, many parameters need to be considered since the development method described can cause an increase in development time. When using Taguchi methods for performance tuning, the load for the development is restrained to maintain enough performance. This method is useful when the number of OCP modules in a SoC are increased.
Related Semiconductor IP
- UFS 5.0 Host Controller IP
- PDM Receiver/PDM-to-PCM Converter
- Voltage and Temperature Sensor with integrated ADC - GlobalFoundries® 22FDX®
- 8MHz / 40MHz Pierce Oscillator - X-FAB XT018-0.18µm
- UCIe RX Interface
Related Articles
- The Future of Embedded FPGAs - eFPGA: The Proof is in the Tape Out
- An 800 Mpixels/s, ~260 LUTs Implementation of the QOI Lossless Image Compression Algorithm and its Improvement through Hilbert Scanning
- How Low Can You Go? Pushing the Limits of Transistors - Deep Low Voltage Enablement of Embedded Memories and Logic Libraries to Achieve Extreme Low Power
- Understanding the Deployment of Deep Learning algorithms on Embedded Platforms
Latest Articles
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS