Performance Evaluation of Inter-Processor Communication Mechanisms on the Multi-Core Processors using a Reconfigurable Device
By Yasue Nagumo, Junji Kitamichi and Kenichi Kuroda
The University of Aizu, Aizuwakamatu JAPAN
Abstract:
Recently, multi-core processors have been featured in embedded field. Especially, with regard to reconfigurable devices, several system constructions can be implemented easily. The Real-Time OS(RTOS) for a multi-core processor has many limitations for system constructions on the reconfigurable devices. Therefore, it is very important to verify that the system construction satisfies the limitations for RTOS and that the primitive system calls operate properly. In addition, when these devices are used in the system development such as task design, the consumption of hardware/software resources, and the performance evaluation of primitive system calls on the reconfigurable devices are very important. In this paper, we propose several inter-processor communication mechanisms for two multi-core processors on an FPGA as the primitive operations for the system tasks and evaluate them. We adopted NIOS II processor as the embedded processors and the TOPPERS/ FMP kernel as the operating system for multi-core processor.
1. Introduction
According to the progress of LSI manufacturing technology, the scale of the system on an LSI chip has been increasing, and the multi-core processor has been featured. It is anticipated that the multi-core processor technology will contribute the improvement of the processor performance. Furthermore, we believe that this improvement trend will continue in the field of embedded processor as well as general-purpose high-performance CPU. For example, the Intel Atom 330[1], NVIDIA Tegra, which adopts ARM ARM11 MPCore, and the RENESAS SH7200[2] and SH7260 series have been developed. For these multi-core embedded processors, several embedded OSs have been proposed for the efficient operation of the target system.
Processors that are configurable on the reconfigurable device are proposed: they are NIOS II [3] by Altera and MicroBlaze[4] by Xilinx and etc. Using these configurable processors, we can configure several system configurations, which include several kinds and numbers of processors, such as those with a multi-cycle/pipeline, with and without cache, and with various kinds and numbers of peripherals and the connections between them.
The Real-Time OS(RTOS) for a multi-core processor has many limitations for system constructions. Therefore, it is very important to verify that the system construction satisfies the limitations for RTOS and that the primitive system calls operate properly. In addition, when these devices are used, in the system development, such as task design, scheduling of the system tasks and the automatic scheduling algorithm of the system tasks, the consumption of hardware/software ressources and performance evaluation of the primitive system calls on the reconfigurable devices are very important.
In this paper, we propose several inter-processor communication mechanisms for two multi-core processors on an FPGA as the primitive operations for the system tasks and evaluate their performance. We adopted the NIOS II processor as the embedded processors, and the TOPPERS/FMP kernel[5] as the operating system for the multi-core processor.
2. Background : NIOS II Processors and TOPPERS OS
In this section, we describe NIOS II processor, which is an embedded processor on FPGA provided by Altera, and TOPPERS/FMP, which is an embedded operating system extended for the multi-core processor.
NIOS II is a 32-bit processor that is configured in an Altera FPGA device. The device can be configured in one of the following three ways: first is a pipeline processor with cache memory, dynamic branch prediction and hardware-macro 1-cycle multiplier, and etc. standard is a pipeline processor which has instruction chache but does not have data cache memory, with static branch prediction and 3-cycle multiplier, and economy is a multicycle processor without cache memory, branch prediction, or hardware-macro multiplier. The former is faster and requires more hardware resources, and the latter is slower and requires fewer hardware resources.
NIOS II can handle several exceptions. NIOS II has 32 input/output ports, and can handle, at maximum, 32 interrupt exceptions for each input port, reset, break, exceptions that are related to Translation Lookaside Buffers(TLBs) and etc.
The NIOS IDE and Quartus II are the design environment for NIOS II processors and Altera FPGA devices, respectively. With the NIOS IDE and Quartus II, the C program can be compiled into memory images, and the processors, memory, application specific logic units and their connectors can be downloaded into on-board target FPGA.
TOPPERS(TOyohashi OPen Platform for Embedded Real-time Systems)[5][6] is an embedded Real-Time OS(RTOS) developed by TOPPERS Project. TOPPERS is an open-source software.
TOPPERS/FMP is an extended OS for multi-core processors that is certified as for the operation on ARM MPCore and NIOS II processors. The features of TOPPERS/FMP are as follows. It is applicable to both Symmetric Multi-Processors(SMP) and Function-Distributed Multi- Processors. Each task is assigned to each processor at the task design-phase. The kernel program does not relocate the tasks to another processor. Using Application Program Interface(API), tasks can transfer themselves to another processor. TOPPERS/FMP kernel has following limitations with regard to its architectures. (a)Each processor must be able to access the program and fixed data in the memory with the same addressing. (b)All processors must access the global memory with the same address, where the common kernel program is allocated. (c)Each processor must be able to issue the interrupt command to other processors( interprocessor interrupt). (d)The system must have the mutual exclusion mechanism of each processor, such as the test & set instruction and mutex. (e)The system must generate more than one lock mechanism using the mutual exclusion mechanism of each processor. (f)Each processor must have an unique ID and be able to identify its own processor using a processor ID.
3. Inter-Processor Communication Mechanisms
We describe the data transfer mechanisms between two processors. The system construction is shown in Figure 1.
Each processor has a local memory and shares a global memory. Hereafter, we treat the data transfer from one local memory to another local memory through the global memory. The unit size of the data transfer is the bit width between the processor and
the global memory. In the performance evaluation, we execute data transfers with different data sizes.
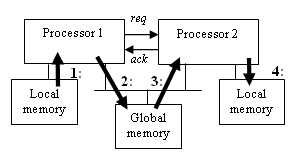
Figure 1. System construction
(a) Polling
The system has two channels: req and ack as hardware resources, and uses a handshake protocol. The pseudo codes of the sending and receiving tasks are shown in Figure 2. The Wait command indicates that the program must stall until the condition is satisfied. Activate and Inactivate commands indicate the transfer the signal:1‘b1 and 1‘b0, to the specified port, respectively. The sending and receiving the signals through the ports and channels indicate the completion of sending and receiving to each other, respectively. In this case, the 2 * N channels and input/output ports are required where the number of processors is N. Datasize indicates the size of data to transfer.
For the exclusion of other tasks access to the data in the global memory and the port req and ack, other mechanisms than those shown in the Figure 2 will be needed. The order in which the data is sent and the data size have to been managed by the sending and receiving tasks.
This mechanism is simple, and the system has no overhead of OS. If the receiving task always polls until the req signal is activated or inactivated, the receiving task starts rapidly. On the other hand, if a task other than the receiving task is running, the response time becomes worse.
The Req and ack signals can be implemented as the two variables in the global memory. In this case, exclusive accesses from other tasks to those variables must be assured. This results in the occurrence of overhead of the access to those variables.

Figure 2. Protocol using polling
(a’) Polling 2
This version is modified protocol of the above-mentioned one and is shown in Figure 3. Using this protocol, one data is sent and received and this operation is repeated Datasize times. In addition, data transfers of 1: & 3 : and 2: & 4: are executed in parallel. This may result in more quick communication.

Figure 3. Protocol using polling 2
(b) Interrupt
The system utilizes two interrupt signals req and ack for the notification of data transfer termination to each other. The pseudo codes of data transfer using interrupt signals and the Interrupt Service Routines(ISRs) are shown in Figure 4. Processor 1 sends the data and activates req in the task _send, and Processor 2 receives the data and activates ack in ISR _req. After receiving the activation of ack, Processor 1 inactivates req in the task _send, and then Processor 2 inactivates ack in the ISR _req. The operation Rei means the REturn from Interruption. Masking the interrupts or ordering the task priority can guard against unexpected parallel access. In this figure, the operations of masking and unmasking interrupts are omitted. Even if anothertask is running, the occurrence of interruption breaks and dispatches the running task, and the receiving task can be launched. However, this results in the occurrence of the overhead of the task dispatch and etc. In this case, N interrupt ports and N output ports are required according to the number of the processors .

Figure 4. Protocol using interrupts
(c)Semaphore
The system utilizes system calls for the semaphore and communicates with other processors using exclusive access to the resources in the global memory. The facility of semaphore is provided by the OS and 2 * N Mutex modules which are IPs provided byAltera. The pseudo codes of data transfer using semaphore are shown in Figure 5.

Figure 5. Protocol using a semaphore
Wei_sem and sig_sem, which are system calls in TOPPERS OS and acquire and release the specified semaphore by a parameter, respectively. Send_done is the variable indicating the termination of sending, is located in the global memory and initialized by 0. Before starting this protocol, both the sending and receiving tasks must share the value of semid which is an identification number of semaphore. In addition, the system must guard send_done and the data area for the data transfer from unexpected access of other tasks. 2 * S Mutex modules in library of SOPC builder are required, where S is the number of semaphore.
4. Performance Evaluation
The environment of performance evaluation is as follows. We adopt DK-START-3C25N provided by Altera as an FPGA board which contains Cyclone III EP3C25F324 FPGA and utilizes a 50MHz clock. The development environments are Quartus II as a fitter to FPGA and NIOS IDE as a cross-compiler(Ver.9.0 SP2). We adopt Modelsim 6.4a as a simulator.We adopt TOPPERS/ FMP 1.0.2.
We construct the target system which consists of two CPUs, two local memories, one global memory and etc. using SOPC builder. We adopt standard and economy NIOS II processors as the core processor. The RTOS is located in each local memory. We decide the address of each memory according to the limitation specified by TOPPERS/FMP kernel. In the case of semaphore protocol, the module Mutex is required. This module is one of default modules in module library of SOPC builder
We show an example of one of constructions using SOPC builder in Figure 6.
In the case of protocols without OS, we compile each program for each processor using NIOS IDE. In the case of the protocol using OS, we compile each program with TOPPERS/FMP kernel program using TOPPERS configurator. The executable ELF files compiled and generated by TOPPERS configurator are translated into HEX files using elf2hex command. Then using HEX memory images, Modelsim simulator executes the total system with OS kernel program and usr programs. In any cases, we use -O2 as the gcc compiler option.
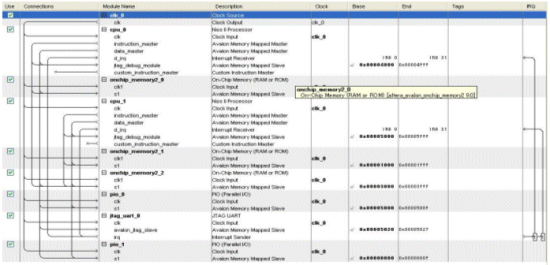
Figure 6. System construction using SOPC builder
In the case of polling, we count the number of clocks from the instruction fetch at the first Wait operation in Processor 1 until the instruction completion of Inactivate ack operation in Processor 2. In the case of interrupt, we count it from the instruction fetch at the first Wait operation in sending task, Processor 1, until the instruction completion of Inactivate ack operation in ISR _req, Processor 2. In this case, we use Hardware Abstraction Layer(HAL) provided by Altera.
In the case of the protocol using semaphore, we count it from the instruction fetch at the system call Wai_sem operation in Processor 1 until the instruction completion of the system call sig_sem in Processor 2.
We use 8, 32 and 128 as the size of data, and measure the number of clocks from execution results. We describe the results in Table 1. The results for economy processor are shown in Figure 7. The comparison between economy and standard processors is shown in Figure 8. We show two cases :polling and polling2.
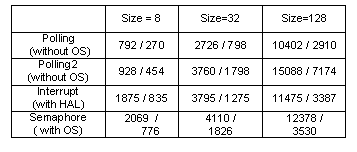
Table 1. Number of clocks for operations
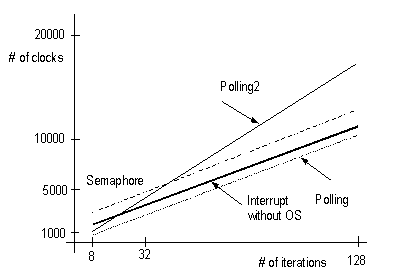
Figure 7 # of clocks for economy processor
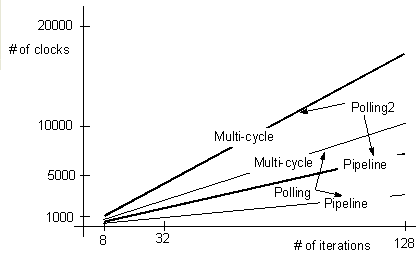
Figure 8 Performance Comparison between Multi-cycle and Pipeline Processors
We verified the correctness of data transfer in any cases using simulation results. In each cell in Table 1, the data on left- and right-hand side are the number of clocks using economy and standard NIOS II processors, respectively.
The number of clocks in the polling protocol is the smallest in any cases. Using semaphore protocol, it takes more than 20,000 clocks to start the user task.
The communication times in Polling2 takes more than those in Polling. The operations for Ack and Req signals require more clock cycles than those decreased by the parallel memory accesses and the compiler can not optimize the operations for the communications between multi-core processors.
Although standard processor requires more hardware resources, the number of clocks required using standard, which is a pipeline processor is smaller than that required when using economy processor in any case.
5. Conclusion
In this paper, we describe several inter-processor communication mechanisms for two multi-core processors on a reconfigurable device and evaluate them. The protocol polling is simple, requires only ports and channels, and is the fastest in any cases. The pipeline standard processor requires more hardwarere sources and can transfer data faster than the multi-cycle economy processer.
A system task can be efficiently designed on the basis of the present results. In future work, we will research the performance of other functions, such as external memory access(SDRAM and etc.), data cache, communications in the same memory(mailbox and etc.), task management and etc. In addition, we will evaluate on more than two processors.
We will develop some applications efficiently using these results and will apply them for the refinement of the algorithms in RTOS and compiler.
References
[1] http://download.intel.com/design/processor/datashts/320528.pdf.
[2] http://documentation.renesas.com/eng/products/mpumcu/rej09b0372_sh7205hm.pdf.
[3] http://www.altera.com/literature/hb/nios2/n2cpunii5v1.pdf.
[4] http://www.xilinx.com/support/documentation/sw_manuals/xilinx11/mb_ref_guide.pdf
[5] http://www.toppers.jp/ (in Japanese)
[6] Hiroaki Takada, “Introduction to the TOPPERS Project Open Source RTOS for Embedded Systems ,” Proceedings of the Sixth IEEE International Symposium on Object-Oriented Real-Time Distributed Computing (ISORC’03) , pp. 44 – 45, 2003.
Related Semiconductor IP
- 8MHz / 40MHz Pierce Oscillator - X-FAB XT018-0.18µm
- UCIe RX Interface
- Very Low Latency BCH Codec
- 5G-NTN Modem IP for Satellite User Terminals
- 400G UDP/IP Hardware Protocol Stack
Related Articles
- Reconfigurable processors make move into big time
- Reconfigurable arrays of processors needed for wireless multimedia
- Optimize inter-processor communication in dual baseband dual mode handsets
- Design of an image-processing device for cost-sensitive, high-volume applications using a novel dynamically reconfigurable technology
Latest Articles
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS
- A Persistent-State Dataflow Accelerator for Memory-Bound Linear Attention Decode on FPGA
- VMXDOTP: A RISC-V Vector ISA Extension for Efficient Microscaling (MX) Format Acceleration
- PDF: PUF-based DNN Fingerprinting for Knowledge Distillation Traceability