High Bit-Rate Controllers for MIPI CSI2
By Yoav Lavi, VLSI Plus, Ltd.
Introduction
The imbalance between I/O speed and internal logic speed in integrated circuits has shifted in recent years in favor of the I/O. While in the past, the performance of integrated circuits was often limited by the I/O rate, today, in both ASICs and FPGAs, internal logic struggles to keep up with the I/O performance.
For example, modern FPGA devices include transceivers that operate at rates exceeding 16Gbps (Giga-bit-per-second), whereas the clock rate of the logic is practically limited to much lower rates, of about 500MHz for carefully optimized units, and 250MHz-300MHz (or sometimes less) for a multi-million-gate logic modules.
This conflict can be solved by massively parallel architectures, at the cost of more silicon area. For example, a 40Gbps I/O stream can be handled by logic circuitry that is clocked at 200MHz, and processes 200 bits per clock.
MIPI CSI2 over DPHY and CPHY
MIPI Alliance is a collaborative global organization with over 300 member companies, serving industries that develop mobile and mobile-influenced devices. Among others, MIPI is developing communication specifications to interface chipsets and peripherals in mobile devices.
Two of the first such specifications are Camera Serial Interface 2 (CSI2), which defines the interface between an image sensor and a processor in a mobile device, and DPHY, which defines the underlying physical layer. The CSI2 and the DPHY specifications were developed, respectively, by MIPI Camera Working Group and MIPI PHY Working Group.
CSI2 defines formats and sequences for the serial transmission of various video datatypes in long and short packets, as well as formats for lower speed communication between CSI2 control and monitoring registers, and a processor. DPHY defines high speed L1 communication over differential wire pairs and includes high-speed mode as well as a slower low-power non-differential mode.
Both the CSI2 and DPHY have evolved (and still evolve) significantly since their conception. Later CSI2 version define communication of numerous video and non-video datatypes, in one to sixteen virtual channels, and include features like Pseudo-Random Bit Scrambling (PRBS), pixel compression, error correction codes, an ultra-low power mode, error handling rules and many others. DPHY has grown in speed, from the original target of 500Mbps per lane (few may remember this today, but the “D” in DPHY stands for Roman D, or 500) to 1Gbps, 1.5G, 2.5Gbps and more to come, and added features such as inter-lane de-skew calibration, line coding and more. In addition, MIPI PHY Working Group developed a unique CPHY specifications, in which high speed data is transferred over triples of balanced wires, (“trios”), at a higher speed. Later CSI2 specifications can use either DPHY or CPHY as the underlying PHY layer.
Developers of CSI2-compliant IP cores often struggle with the need to generate logic circuitry that is fast enough to handle the high data rate of DPHY or CPHY, and yet limit the logic circuit clock rate for easy timing closure. For example, according to CSI2, data to be transmitted on DPHY lanes is sent in bytes, but a 2.5Gbps DPHY lane, if handled a byte at a time, requires a 312.5MHz clock, which is not an easy task for large amount of logic. When four fata lanes are used, the byte rate is 1.25GHz.
VLSI Plus solution
To provide an answer to the potential I/O – internal logic speed imbalance in the recent CSI2/DPHY specifications, VLSI Plus is introducing two new IP cores - the SVTPlus2500 serial video transmitter and the SVRPlus2500 serial video receiver. Both cores can handle four 2.5Gbps data lanes, with internal clock frequency well below 200MHz.
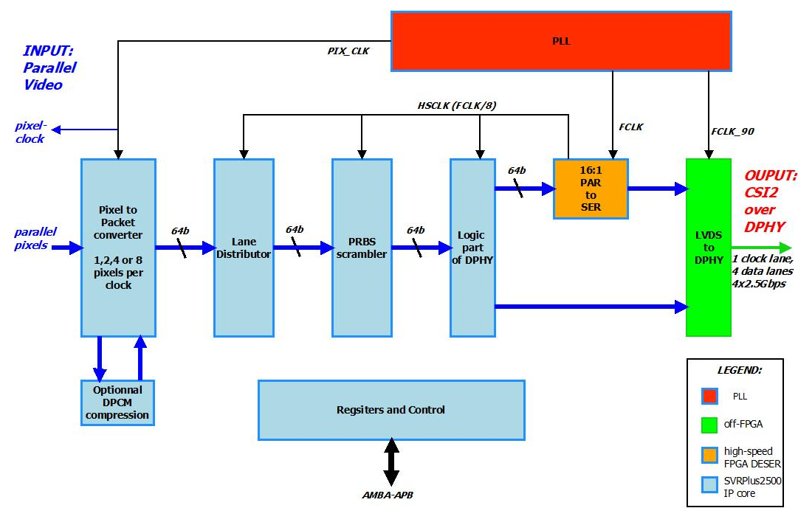
SVTPlus2500F (FPGA version of the SVTPlus2500) Internal Structure
The SVTPlus2500 receives a parallel video stream, processes the stream, and transmits MIPI CSI2 video over four DPHY data lanes, with up to 2.5Gbps per lane. In the SVTPlus2500F (the FPGA version of the IP) high-speed processing is confined to two in-chip locations and to an off-chip device:
- An FPGA PLL module, which outputs two phase-shifted clocks (FCLK and FCLK-90) at half the lane bitrate (e.g., 1.25Gbps for 2.5Gbps per lane).
- A 16:1 parallel-to-serial converter, which is implemented at the I/O level of the FPGA and is typically provided by the FPGA vendor.
- An LVDS to DPHY off-FPGA device, available from third party sources.
In addition to the FCLK and FCLK_90 clocks, the SVTPlus2500 includes three other clocks – a slow clock that is used for register-I/O (and will not be discussed below) and two medium frequency clocks: a PIX_CLK and a HSCLK, both generated by the PLL.
PIX_CLK is used to clock pixels from an external video source to the SVTPlus2500, and to convert the pixels to packets. The SVTPlus2500 receives parallel consecutive pixels in each PIX_CLK tick: 4-pixel per clock for pixels with BPP (bit-per-pixel) > 16, 8-pixel per clock for pixels with 8<BPP<=16, and 16-pixel per clock for BPP<8. For example, for RAW10 (BPP=10), to keep up with 4 2.5Gbps lanes (10Gbps total), the SVTPlus2500 inputs 1G 10-bit-pixels per second. At 8-pixel per clock, this translates to PIX_CLK frequency of 125MHz. In another example, the SVTPlus2500 receives four RGB888 24-bit pixels per clock. to keep up with an output rate of 10Gbps, the PIX_CLK frequency is equal to 10G/(24*4) ≈ 104MHz.
PIX_CLK is generated by the PLL, according to the formula:
PIX_CLKf = FCLKf * 2 * 4 /(BPP*pixel-per-clock)
HSCLK is used to clock lane data in the internal SVTPlus 64-busses, from the PIX_CLK input stage to the parallel-to-serial converters. At maximum output rate of 2.5Gbps*4 = 10Gbps, the 64-bit busses are clocked at 10Gbps/64 =156.25Mhz. HSCLK is generated by dividing FCLK by 8.
___________
The SVRPlus2500 receives CSI2 packets over four DPHY data lanes at up to to 2.5Gbps per lane, processes the packets and outputs parallel consecutive pixels.
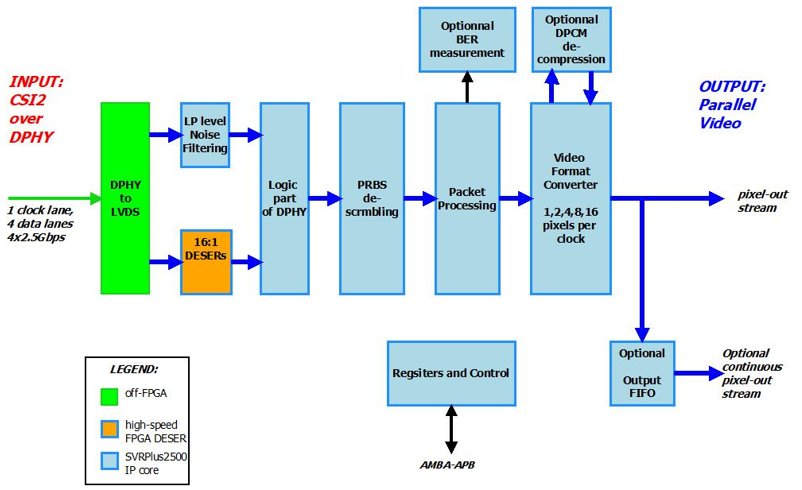
SVRPlus2500F (FPGA version of the SVRPlus2500) Internal Structure
Unlike the SVTPlus2500, the SVRPlus synchronizes the lane data rate to an internal SVR_FCLK clock, which is then used exclusively throughout the datapath. The four DPHY data lanes are converted to LVDS levels by an off-FPGA device, available from third party sources, and then converted to 16-bit parallel stream (for each data lane). The 1:16 serial-to-parallel converters are implemented at the I/O level of the FPGA and are typically provided by the FPGA vendor.
Each 2.5Gbps lane is converted to a 16-bit input bus that is clocked at 2.5G/16 = 156.25MHz; the input buses are synchronized to the SVR_FCLK (the frequency of SVR_FLCK should be equal to or higher than the input lane data rate divided by 16).
At the output, the SVRPlus2500 outputs several consecutive pixels per clock: 4-pixel per clock for pixels with BPP (bit-per-pixel) > 16, 8-pixel per clock for pixels with 8<BPP<=16, and 16-pixel per clock for BPP<8. Output pixels are clocked by SVR_FCLK, with a pixel-valid qualifier. (The customer can add an optional output-FIFO, which is clocked by an additional clock, slower than SVR_FCLK, to get contiguous output streams, with no Valid qualifier.)
___________
The clock frequency requirements for the SVRPlus2500 and the SVTPlus2500 IP cores are summarized in the following table. In all cases, video transfer rate is 10Gbps (four 2.5G data lanes) – sufficient, for example, for 30FPS 8K video (7680x4320) at 10-bit per pixel.
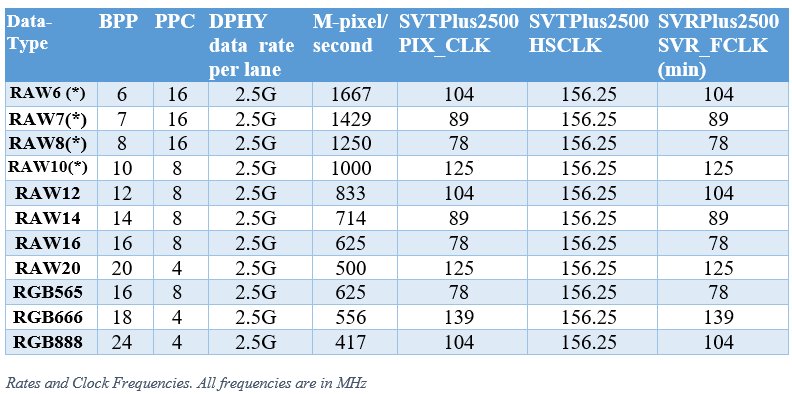
Rates and Clock Frequencies. All frequencies are in MHz
(*) – also applicable to RAW10 and RAW12 pixel formats that are compressed to 6,7,8 or 10 bits.
___________
Calibration
For operation beyond 1.5Gbps per lane, the DPHY specifications define a calibration sequence that a DPHY source sends. The DPHY sink detects the calibration sequence and calibrates the inter-lane skew. Two types of calibration sequences are defined – initial calibration, which should be sent once upon link initialization, and periodic calibration, which is sent periodically.
The calibration sequence starts with the transmission of 16 logic-1 bits, followed by a long sequence of 010101…
The sequence of 010101… should be transmitted:
- for the initial calibration sequence – at least for 215 UI, and at most for 100μS
- for the periodic calibration sequence – at least for 210 UI, and at most for 10μS
(UI is a DPHY term defined as the time needed to transmit one bit in each data-lane; for example, at 2.5Gbps, UI = 400ps.)
The SVTPlus2500 includes two registers that store the lengths of initial and periodic calibration sequences. Sending the calibration sequences is typically initiated by writing to a register or by pulsing an input pad.
The SVRPlus2500 asserts a Calibration-On output when detecting the calibration sequence. The FPGA’s serial-to-parallel converters then adjust the corresponding delays (from the clock lane), to minimize the skew between the data lanes.
___________
Compression
To allow higher video rates in terms of pixel-per-second and without increasing the PHY data rate, MIPI CSI2 specifications define high quality DPCM pixel compression, which facilitates:
- Compression of RAW8 8-bit pixels to 6 or 7 bits
- Compression of RAW10 10-bit pixels to 6,7 or 8 bits
- Compression of RAW12 12-bit pixels to 6,7,8 or 10 bits.
The compression algorithm is designed such that the perceived image quality is hardly affected, especially in low compression ratios.
If RAW12 pixels are compressed to 10-bit in the 8K video example cited above, a 12-bit-per-pixel 30FPS, 8K (7680x4320) video could be transmitted using 4 2.5Gbps DPHY lanes with virtually no perceivable drop in image quality.
Registers in the SVTPlus2500 can be used to define video compression in any of the supported CSI2 schemes. Registers in the SVRPlus2500 can be used to define a compatible decompression scheme.
___________
Virtual Channels
CSI2 specifications define virtual channels that can be used to multiplex video sources over a single underlying PHY. The virtual channel information is encoded in the packet header, including two explicit virtual channel header bits and two bits which are encoded within the ECC (error correction code) field of the header.
Virtual channels can be used, for example, to differentiate between special video lines generated by image sensors, such as optical black, embedded data and video. In other applications, the virtual channels may be used to multiplex inputs from several video sources.
In the figure below, up to 16 video sources are multiplexed in a source ASIC / FPGA, by applying different Virtual-Channel codes at the Virtual-Channel input of an SVTPlus2500 IP core, to differentiate between the sources. The multiplexed video is transmitted at 10Gbps over four DPHY data lanes (and a single clock lane) to a sink ASIC / FPGA.
The sink ASIC / FPGA includes an SVRPlus2500 IP core, which receives the DPHY video stream and outputs parallel pixels with virtual-channel indication. The video streams of the 16 video sources are stored in a shared memory. The virtual-channel indication that the SVRPlus2500 outputs is used to select segments in the shared memory.
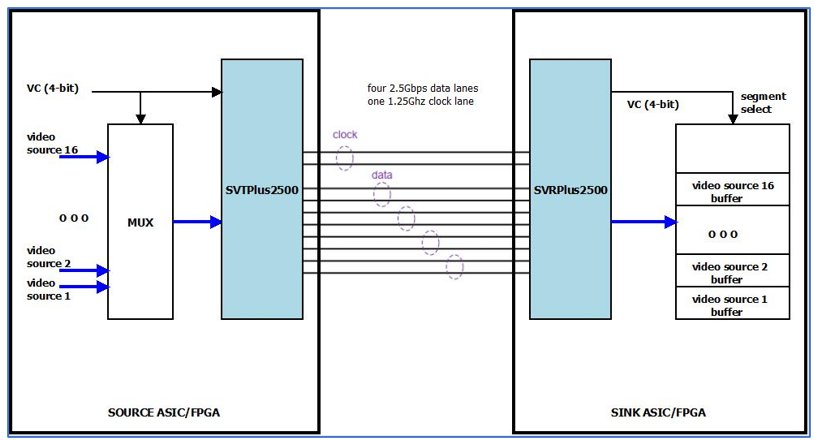
Using Virtual Channels to Multiplex Video Sources
___________
PRBS
When static video images are transferred from a video source to a video sink, noise associated with the transmission may be unevenly distributed in the frequency domain and, in particular, narrow frequency bands may be subject to high noise.
For example, if an image sensor transmits a test pattern of vertical black (all-0) and white (all-1) stripes, the video spectrum will have a strong component that corresponds to the frequency of the vertical stripes, and virtually no other component (below the transmission clock frequency).
The transmission energy generates noise in several locations:
- At the transmitting ASIC / FPGA – due to imbalances in the differential I/O buffers, the power consumption to transmit a logic-1 is different from that of a logic-0. Difference in the power-supply current translates to voltage drops, which may propagate in the transmitting ASIC/FPGA.
- Similarly, at the receiving ASIC/FPGA, receiving a logic 1 or a logic 0 result in different power consumptions due to imperfection of the differential receiver circuits; the difference in power consumption may translate to current spikes and voltage drops, which propagate in the receiving ASIC/FPGA.
- As a result of imperfections in the data lane wires, the differential pairs transmit noise, which may be induced in adjacent wires.
To mitigate the effect of transmission noise, CSI2 defines a Pseudo-Random-Bit Sequencing operation, in which all transmitted data is scrambled by a pseudo random sequence, separately for each of the data lanes.
VLSI Plus SVTPlus2500 includes a PRBS scrambler, which can be used to scramble the data and evenly spread the transmission noise in all frequency bands, from half the clock frequency to the horizontal frequency of the video source. VLSI Plus SVRPlus2500 unscrambles the scrambled transmission.
___________
A product brief of the SVTPlus2500 can be download here: SVTPlus2500 Product Brief
A product brief of the SVRPlus2500 can be download here: SVRPlus2500 Product Brief
For more information, please contact us at ip_producst@vlsiplus.com
Related Semiconductor IP
Related Articles
- Generating High Speed CSI2 Video by an FPGA
- A design of High Efficiency Combo-Type Architecture of MIPI D-PHY and C-PHY
- Driving ADAS Applications with MIPI CSI-2
- PCIe 5.0: The universal high-speed interconnect for High Bandwidth and Low Latency Applications Design Challenges & Solutions
Latest Articles
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks
- Assertain: Automated Security Assertion Generation Using Large Language Models
- VolTune: A Fine-Grained Runtime Voltage Control Architecture for FPGA Systems
- A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators
- Quantifying Uncertainty in FMEDA Safety Metrics: An Error Propagation Approach for Enhanced ASIC Verification