Creating core independent stimulus in a multi-core SoC verification environment
Ankit Khandelwal, Gaurav Jain, Abhinav Gaur (Freescale Semiconductors, India)
Introduction
With time, the size and complexity of System-On-Chip (SoC) design is increasing rapidly. More and more functionality is getting integrated into a single device. The instrument cluster/safety devices with single and multiple high resolution displays necessitates the requirement of multi-core architecture with real time and application processors. These different processors enable great capability for the software. But this kind of architecture imposes great challenge for the verification of different modules/blocks which can be run by the different processors in the system.
The type of processors used in the multi-core architecture can be similar, like in safety critical SoCs - where two cores are working in lock step mode; or different, such as real time and application processors used in graphics and computation intensive applications. Generally real time processors are slower than the application processors. The stimulus (or test case) developed to run on one processor, when run on other processor, can cause different issues if not coded properly. Verification engineers should take care of certain things while developing such cases so that the debug effort and time can be reduced in an already constrained design cycle time. This article tries to list down a few points which if taken care at the time of developing patterns in a multi-core architecture, can prove to be of great help. The below figures shows a basic multicore SoC with 2 processors which can access a same peripheral (Paths shown in bold black line).
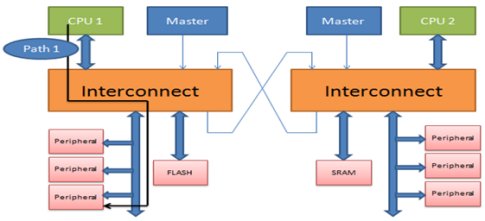
Figure - 1
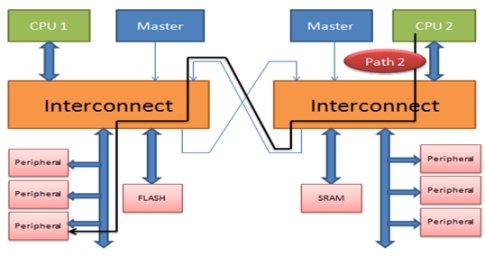
Figure - 2
Points to be kept in mind while developing test cases in a multi-core environment
1. Using deterministic delays:
Many times in test cases, delays are inserted in between and expect some event to happen during that time delay, so that the next logical step or check can take place in the test case after that event has occurred. For example, some event is triggered in the SoC and it takes some cycles to complete and for executing the next instruction we want that event to get complete. So we insert some delay after the triggering instruction and expect that event to get finished during that time delay. Now this delay when converted to time may be dependent on core based on the speed at which that core is running.
An example for such scenarios is the use of “for” loops. Suppose a small for loop is inserted in code and one processor is taking around 20us to execute that loop and we have kept this value keeping in mind the time taken by this processor. Now moving to different processor which is faster, let’s say two times, this loop will be exhausted in 10us. So if there is some event in a test case which takes 15us to occur will work correctly for the slower core (since it waits for 20us), but fails for the faster core which takes 10us to execute that loop, thus disturbing the logical flow of the testcase. So the stimulus/test-case should be developed keeping this factor in mind. A better practice would be to wait for some status bit of a register present in the design or an interrupt event and then moving ahead. Now, till the time the interrupt or trigger hasn’t occurred, the core will not execute the next piece of code. In fact, this is applicable even when there is one core and stimulus is run with cache enabled and disabled. The speed is significantly increased with cache enabled.
2. Defines based approach instead of hard coded numbers
There are a lot of ways to explain this statement. For example, generally all the modules in a SoC have an interrupt which is connected to the core as an indication to perform some routine in the event of interrupt. These interrupts may be mapped to more than one cores in the system. All the cores which have the interrupts mapped must be able to service the interrupt correctly. Now, generally in a system, the interrupt mapping number is different for different cores. Let us understand it with the below mentioned example.
Let’s say, one interrupt is mapped to number 20 of one core and 52 of another core. In test-cases, we install the interrupt handlers and pass this interrupt number and define a routine associated with this interrupt number which has to be executed in case the interrupt occurs. If hardcoded numbers are used in the cases for such handlers, case may work for one core which is the main core but may not work for the second core as the interrupt number is different for the second core. In such cases, a better practice is to use some define in the test cases and that define can be given some value based on the processor which is executing the test case in some common file of the test-bench. In this way, the stimulus will remain intact and will work seamlessly with either of the two cores. Similarly, all other factors that are different for the various cores present on the system should be managed via some define which gets its value depending on the core on which test case is running to avoid all such scenarios.
3. C-side compilation switches must be passed as arguments and not as defines.
The various phases of a testcase are often guarded by a define. If that define is passed, that part of the testcase is expected to be used. This is needed since different test-cases may or may not want to use a check present in a common function of the test-bench. For example, a part of C-code present in a common function is guarded as follows:
#ifdef TASK_A
<Piece of code doing some status check>
<Piece of code>
<Piece of code doing some register configuration>
< Piece of code >
#endif
These defines should be passed as arguments which control the C-side compilation of the stimulus, otherwise, the define maybe present when code is compiled for one core and may not be present when the code is compiled for another core. This will further lead to difference stimulus running when test-case is running on different cores. This creates a lot of unnecessary debug effort and should be always be kept in mind while passing such defines. In short, such defines must be visible to all the possible cores which can be used to run the stimulus.
4. Availability of various aspects of the design to the various cores:
There are various IPs, memories, etc. present in the design which may be available differently to each of the cores. For example, a SoC is having 1MB of SRAM – Core 1 can access the entire 1MB region whereas Core 2 can access only the first 512KB. The last 512KB region of SRAM happens to be reserved for the second core. In such a scenario, if you are creating a test-case which checks the accesses to SRAM, you must keep in mind that when this test-case is running on the second core, the accesses for last 512KB must not be done and that region should be expected as reserved region. This can be done by guarding this portion of the test case by a define which gets passed only when the testcase is compiled for first core.
5. Variables should be defined as volatile to avoid any potential issue:
The volatile keyword is intended to prevent the compiler from applying any optimizations on objects that can change in ways that cannot be determined by the compiler. Again this is processor specific and might be applicable for one processor and not for other. Therefore, it becomes important in case of multicore environment where different types of processors are used.
Objects declared as volatile are omitted from optimization because their values can be changed by code outside the scope of current code at any time. The system always reads the current value of a volatile object from the memory location rather than keeping its value in temporary register at the point it is requested, even if a previous instruction asked for a value from the same object. So the simple question is, how can value of a variable change in such a way that compiler cannot predict. Consider the following cases for answer to this question.
Global variables modified by an interrupt service routine outside the scope: For example, a global variable can represent a address in the memory which will be updated dynamically. The variable must be declared as volatile in order to fetch latest data available for the variable always from the memory location. Failing to declare variable as volatile, the compiler will optimize the code in such a way that it will read the port only once and keeps using the same value in a temporary register to speed up the program (speed optimization). In general, an ISR used to update these global variables when there is an interrupt due to availability of new data.
6. Ordering model of the Masters:
Real time processors are generally AHB masters which does not support out of order transactions and require the previous transaction to get complete before issuing new transaction. But application processors are generally AXI masters which enable out of order transaction issuing and completion. The ability to complete transactions out of order means that transactions to faster memory regions can complete without waiting for earlier transactions to slower memory regions. This feature can also improve system performance because it reduces the effect of transaction latency. The ability to issue multiple outstanding addresses means that masters can issue transaction addresses without waiting for earlier transactions to complete. This feature can improve system performance because it enables parallel processing of transactions. Proper care should be taken while writing the stimulus to avoid any unintended action happening in the system.
Case 1:
Suppose we are incrementing a variable before issuing a reset to the system and reading the updated value of the variable after coming out of reset. Now, if the master core issues the reset command prior to the incrementing variable in compliance with its ordering model, then it might happen that the reset command completes and system gets reset first with the variable value never getting incremented. So in such cases the value read after reset might be wrong and can lead to undesirable failures in the system.
Case 2:
It might happen that the master is performing accesses to 2 different memory regions in the system in a particular sequence. With the AHB master, it will work fine but with AXI master out of order ordering model, this sequence might get disturbed causing the functional failure even though the test-case was written taking care of this sequence. The solution to such issues might be the use of switches which can cause the AXI masters to perform ordered transactions.
Case 3:
As a part of the init sequence of some module, suppose we were giving a software reset to state machines and logic inside IP by issuing a reset assert command followed by a reset de-assert command. With AHB master core this logic worked perfectly fine as the command will be executed in sequence and in the next command will be given only when the previous command is finished. Now with AXI masters, the commands get pipelined for faster execution. The commands were stored in a FIFO inside the IP. It was happening that the reset de-assert command was getting stored in FIFO and then the reset was propagating inside the IP. Due to this, the FIFO was also getting cleared and the IP did not give any valid response for the command causing system to hang. Delay was then added between the two commands as a part of the init sequence
Figure - 3
As can be seen in the above figure, the reset (sys_rstN) got asserted after the next instruction was pushed into the FIFO. With the reset assertion (causing the apb_mlast to get de-asserted) the FIFO got flushed and the response to the reset de-assert was not given by IP.
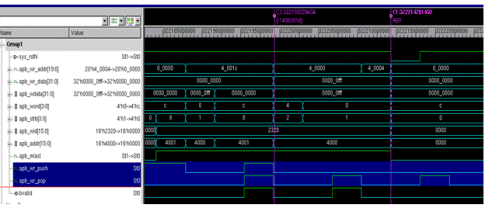
Figure - 3
As can be seen in the above figure, the reset (sys_rstN) got asserted after the next instruction was pushed into the FIFO. With the reset assertion (causing the apb_mlast to get de-asserted) the FIFO got flushed and the response to the reset de-assert was not given by IP.
Conclusion:
The above cited examples are the most common issues faced in a multicore environment when multiple cores can be used to run the same stimulus. With a little intelligence and understanding while developing patterns for such environment, a lot of effort and debug time can be prevented which is the requirement in already crunched timelines in present day SoC’s.
Related Semiconductor IP
- NPU IP Core for Mobile
- NPU IP Core for Edge
- Specialized Video Processing NPU IP
- HYPERBUS™ Memory Controller
- AV1 Video Encoder IP
Related White Papers
- SOC Stability in a Small Package
- An efficient way of loading data packets and checking data integrity of memories in SoC verification environment
- Reducing DFT Footprints: A Case in Consumer SoC
- Creating SoC Integration Tests with Portable Stimulus and UVM Register Models
Latest White Papers
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions
- Automating NoC Design to Tackle Rising SoC Complexity
- Memory Prefetching Evaluation of Scientific Applications on a Modern HPC Arm-Based Processor