VeriSilicon's Vivante VIP8000 Neural Network Processor IP Delivers Over 3 Tera MACs Per Second
Groundbreaking IP brings real-time 1080p scene classification, object detection, and pixel segmentation to embedded devices.
SANTA CLARA, Calif.-- May 03, 2017 -- VeriSilicon Holdings Co., Ltd. (VeriSilicon), a Silicon Platform as a Service (SiPaaS®) company, today announces VIP8000, a highly scalable and programmable processor for computer vision and artificial intelligence. It delivers over 3 Tera MACs per second, with power consumption more efficient than 1.5 GMAC/second/mW and the smallest silicon area in industry with 16FF process technology.
The Vivante VIP8000 consists of a highly multi-threaded Parallel Processing Unit, Neural Network Unit and Universal Storage Cache Unit. VIP8000 can directly import neural networks generated by popular deep learning frameworks, such as Caffe and TensorFlow and neural networks can be integrated to other computer vision functions using the OpenVX framework. It supports all current popular neural network models (including AlexNet, GoogleNet, ResNet, VGG, Faster-RCNN, Yolo, SSD, FCN, and SegNet) and layers (including convolution and deconvolution, dilation, FC, pooling and unpooling, various normalization layers and activation functions, tensor reshaping, elementwise operation, RNN and LSTM features) and is designed to facilitate adoption of new neural networks and new types of layers. The Neural Network Unit supports both fixed-point 8-bit precision and floating-point 16-bit precision, and supports mixed-mode applications to achieve the best computational efficiency and accuracy.
Vivante VIP8000’s VIP-Connect™ interface allows rapid customer integration of application-specific hardware acceleration units to work collaboratively with the standard Vivante VIP8000 hardware units.
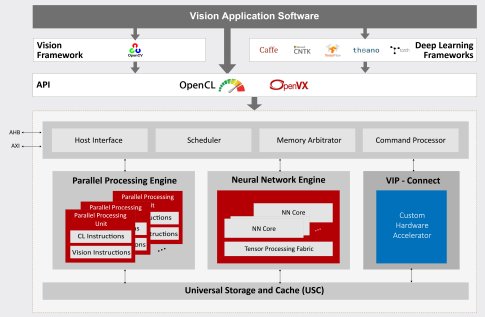
The processor is programmed by OpenCL or OpenVX with a unified programming model across the hardware units, including customer application-specific hardware acceleration units. All the hardware units work concurrently, with shared data in cache to significantly reduce the bandwidth.
To better address embedded products across different market segments, Vivante VIP8000 is highly configurable, including through independent scalability of the Parallel Processing Unit, Neural Network Unit and Universal Storage Unit, and the ACUITY™ SDK provides training and a complete set of IDE tools.
“Neural Network technology is growing and evolving rapidly, and Vivante VIP8000’s use cases are expanding beyond the original surveillance camera and automotive customer base. Vivante VIP8000’s superior PPA (Performance, Power, Area), the innovations in bandwidth reduction through patent-pending universal cache architecture, and compression algorithms speed up the movement to enable embedded devices to be AI terminals collaborating with cloud to deliver revolutionary AI experiences to the end user,” said Wei-Jin Dai, Executive Vice President, Chief Strategy Officer, VeriSilicon.
“To enable rapid growth in AI in embedded devices, highly-efficient and powerful programmable engines with industry standard APIs like OpenCL and OpenVX are critical. The efficiency will come from both neural network innovation and increased computing density,” said Jon Peddie, President, JonPeddie Research.
For more information, please visit www.verisilicon.com .
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related News
- Neural Network Inference Engine IP Core Delivers >10 TeraOPS per Watt
- VeriSilicon's Neural Network Processor IP Embedded in Over 100 AI Chips
- Hexagon Semi’s HX77 AR Display Processor Achieves Ultra-Low Power Consumption with VeriSilicon’s Nano IP Portfolio
- VeriSilicon Expands SoC Platform with Vivantes Silicon Proven Graphics Solutions
Latest News
- Arasan acheives the Industry's First ASIL-D Certification for its CAN XL IP Core
- Quintauris and Elektrobit Partner to Enable Reliable RISC-V Solutions for Automotive
- Wind River Joins the CHERI Alliance and Collaborates with Innovate UK to Accelerate Cybersecurity Innovation
- Arteris and MIPS Partner to Accelerate Development for Physical AI Platforms
- DCD-SEMI expands CryptOne with EdDSA Curve25519 IP core for secure embedded systems