芯原推出Vivante VIP8000神經網路處理器IP,每秒可提供超過3 Tera MAC
突破性的IP為嵌入式裝置提供即時1080p場景分類、物件偵測和像素分割。
加州聖塔克拉拉-- May 03, 2017--晶片設計平臺即服務(Silicon Platform as a Service,SiPaaS®)提供商芯原股份有限公司(芯原)今日宣佈推出一款電腦視覺和人工智慧應用的高度可擴展和可程式設計的處理器VIP8000。它每秒可提供超過3 Tera MAC,功耗效率高於1.5 GMAC /秒/兆瓦,是業界面積最小的採用16FF製程技術的處理器。
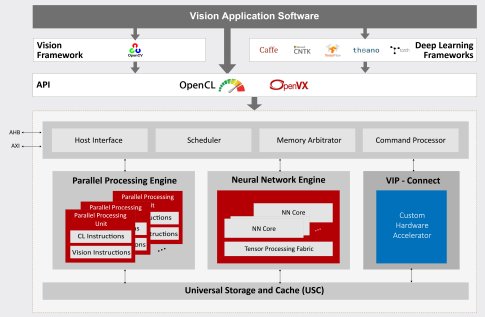
Vivante VIP8000由高度多執行緒的平行處理單元、神經網路單元和通用儲存快取單元組成。VIP8000可以直接匯入由Caffe和TensorFlow等主流深度學習架構生成的神經網路,並可利用OpenVX架構將神經網路整合到其他電腦視覺功能模組中。它支援當前所有的主流神經網路模型(包括AlexNet、GoogleNet、ResNet、VGG、Faster-RCNN、Yolo、SSD、FCN和SegNet)和層類型(包括卷積和去卷積、擴張、FC、池化和去池化、各種規範化層和啟動函數、張量重塑、逐元素運算、RNN和LSTM功能),旨在促進新型神經網路和新型層的採用。神經網路單元支援定點8位元精度和浮點16位精度,並支援混合模式應用,以達到最佳計算效率和準確率。
Vivante VIP8000的VIP-Connect™介面支援客戶快速整合專用硬體加速單元,使其與標準的Vivante VIP8000硬體單元實現協同運作。
該處理器由OpenCL或OpenVX進行程式設計,並在含客戶專用硬體加速單元在內的硬體單元中採用統一的程式設計模型。所有硬體單元同時工作,共用快取資料,可顯著減少頻寬。
為了加強因應不同市場區塊的嵌入式產品,Vivante VIP8000可以靈活配置,其平行處理單元、神經網路單元和通用儲存單元分別具有可升級性,且ACUITY™ SDK可提供培訓和全套IDE工具。
芯原執行副總裁兼首席戰略官戴偉進表示:「神經網路技術正在快速成長和演進,Vivante VIP8000的用例範圍拓展到最初的的監視器和汽車電子客戶群之外。Vivante VIP8000以其優越的PPA(性能、功耗、面積),透過正在申請專利的通用快取架構來降低頻寬的創新之舉,以及壓縮演算法,加快了將嵌入式裝置作為AI終端且與雲端協作,為終端使用者提供革命性AI體驗的行動。」
JonPeddie Research總裁Jon Peddie表示:「為了在嵌入式裝置中實現AI的快速成長,支援OpenCL和OpenVX等業界標準API的高效且功能強大的可程式設計引擎可謂至關重要。神經網路創新和增加計算密度將共同提升效率。」
如欲瞭解更多資訊,請造訪www.verisilicon.com。
Related Semiconductor IP
- UCIe D2D Adapter & PHY Integrated IP
- Low Dropout (LDO) Regulator
- 16-Bit xSPI PSRAM PHY
- MIPI CSI-2 CSE2 Security Module
- ASIL B Compliant MIPI CSI-2 CSE2 Security Module
Related News
- 神经网络推理引擎IP核提供> 10 TeraOPS每瓦特
- DSP Group推出带有专用神经网络推理处理器的DBM10低功耗Edge AI / ML SoC
- 六角形半导体的天相芯HX77采用芯原Nano IP组合,打造超低能耗AR显示处理器
- Xilinx投资一家致力于神经网络构架的公司作为其数据中心生态系统发展计划的一部分