Expedera’s Origin Evolution NPU IP Brings Generative AI to Edge Devices
- Expedera launches its Origin Evolution NPU IP, bringing hardware acceleration to meet the computational demands of running LLMs on resource-constrained edge devices.
- New purpose-built hardware and software architecture runs LLMs and traditional neural networks with ultra-efficient PPA, providing fully scalable NPU IP solutions.
- Origin Evolution NPU IP solutions are suitable for applications ranging from smartphones to automotive to data centers and are available now.
Santa Clara, California, May 20, 2025 — Expedera Inc., a leading provider of scalable Neural Processing Unit (NPU) semiconductor intellectual property (IP), launched its new Origin Evolution NPU IP today. This innovative technology advances Generative Artificial Intelligence (GenAI) capabilities in edge devices. Origin Evolution effectively manages the unique workload requirements of running LLMs on resource-constrained devices, as well as CNNs (Convolutional Neural Networks) and RNNs (Recurrent Neural Networks).
Running LLM inference in edge hardware is crucial because it reduces latency and eliminates security concerns associated with cloud-based implementations. However, deploying LLMs in resource-constrained systems poses challenges due to their large model sizes and significant computational requirements. Consequently, edge designs require specialized hardware that can effectively address their unique resource constraints, including power, performance, area (PPA), latency, and memory requirements. Moreover, innovative software optimizations are essential, including model compression, hardware optimization, attention optimization, and the creation of dedicated frameworks to manage computational and energy constraints at the edge.
“Origin Evolution is a radical advancement providing an AI inference engine with out-of-the-box compatibility with popular LLM and CNN networks, that produces ideal results in applications as varied as smartphones, automobiles, and data centers,” said Siyad Ma, CEO and co-founder of Expedera. “It builds on our years of engineering advancements and is incredibly exciting for our customers and the myriad brands that want to utilize GenAI in their products.”
Scalable to 128 TFLOPS in a single core and to PetaFLOPS and beyond with multiple cores, Origin Evolution can be configured to produce optimal PPA results in a wide range of applications. Origin Evolution significantly reduces memory and system power needs while increasing processor utilization. Compared to alternative solutions, its packet-based processing reduces external memory moves by more than 75% for Llama 3.2 1B and Qwen2 1.5 B. Even in highly memory-bound use cases, Origin Evolution excels in producing 1000s of effective TFLOPS and dozens of tokens per second per mm2 of silicon.
Origin Evolution can support custom and ‘black box’ layers and networks, while offering out-of-the-box support for today’s most popular networks, including Llama3, ChatGLM, DeepSeek, Qwen, MobileNet, Yolo, MiniCPM, and many others. Origin Evolution NPU IP solutions are available now and are production-ready and silicon-proven in customer production designs.
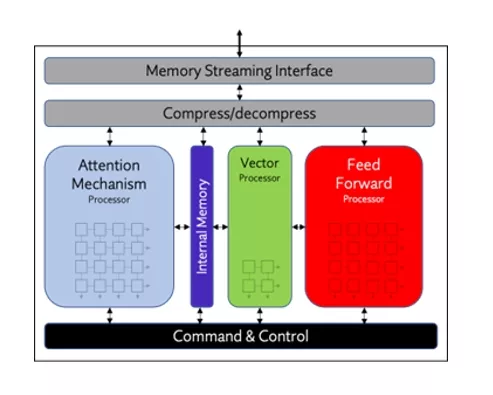
Origin Evolution NPU IP uses Expedera’s unique packet-based architecture to achieve unprecedented NPU efficiency.
Origin Evolution allows users to implement existing trained models with no reduction in accuracy and no retraining requirements, with confidence in achieving ideal PPA. It uses Expedera’s unique packet-based architecture to achieve unprecedented NPU efficiency. Packets, contiguous fragments of neural networks, overcome the hurdles of large memory movements and differing network layer sizes, which LLMs exacerbate. The architecture routes the packets through discrete processing blocks, including Feed Forward, Attention, and Vector, which accommodate the varying operations, data types, and precisions required when simultaneously or separately running LLM and CNN networks. Origin Evolution includes a high-speed external memory streaming interface compatible with the latest DRAM and HBM standards. Complementing the hardware stack is an advanced software stack, featuring support for network representations from HuggingFace, Llama.cpp, TVM, and others. It supports full integer and floating-point precisions (including mixed modes), layer fusion and fissions, and centralized control of multiple cores within a chip, chiplet, or system.
About Expedera
Expedera provides customizable neural engine semiconductor IP that dramatically improves performance, power, and latency while reducing cost and complexity in edge and data center AI inference applications. Successfully deployed in 10s of millions of devices, Expedera’s Neural Processing Unit (NPU) solutions are scalable and produce superior results in applications ranging from edge nodes and smartphones to automotive and data center inference. The platform includes an easy-to-use software stack that allows the importing of trained networks, provides various quantization options, automatic completion, compilation, estimator, and profiling tools, and supports multi-job APIs. Headquartered in Santa Clara, California, the company has engineering development centers and customer support offices in the United Kingdom, India, China, Taiwan, and Singapore. Visit https://www.expedera.com
Related Semiconductor IP
- AI inference engine for Audio
- Neural engine IP - AI Inference for the Highest Performing Systems
- Neural engine IP - Tiny and Mighty
- Dataflow AI Processor IP
- Powerful AI processor
Related News
- Expedera Introduces Its Origin Neural Engine IP With Unrivaled Energy-Efficiency and Performance
- Google Open-Sources NPU IP, Synaptics Implements It
- VeriSilicon and Google Jointly Launch Open-Source Coral NPU IP
- VeriSilicon’s NPU IP VIP9000NanoOi-FS has achieved ISO 26262 ASIL B certification
Latest News
- Global Semiconductor Sales Increase Substantially in February
- Hardware Root of Trust Essential for AI Chip Integrity
- AI Compute Demand Drives 44% YoY Growth for Top 10 Global Fabless IC Firms in 2025
- IBM Announces Strategic Collaboration with Arm to Shape the Future of Enterprise Computing
- Rambus Unveils HBM4E Controller: 16 GT/s, 2,048-Bit Interface, Enabling C-HBM4E