Vision DSP IP
Filter
Compare
32
IP
from
6
vendors
(1
-
10)
-
Tensilica Vision P1 DSP
- 256/128b Load/Store capabilities
- 128 8-bit MAC
- 8/16/32-bit fixed-point processing
- Single-precision (FP32) and half-precision (FP16) floating-point processing
-
Tensilica Vision P6 DSP
- 1024/512b Load/Store capabilities
- 256 8-bit MAC
- 8/16/32-bit fixed-point processing
- Single-precision (FP32) and half-precision (FP16) floating-point processing
-
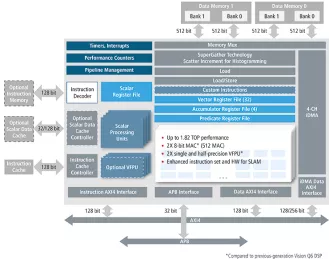
Tensilica Vision Q8 DSP
- 2048/1024b Load/Store capabilities
- 1024 8-bit MAC: 2X MAC capability versus Vision Q7 DSP
- 8/16/32-bit fixed-point processing
- Double-precision (FP64), single-precision (FP32), and half-precision (FP16) floating-point processing
-
Vision AI DSP
- Ceva-SensPro is a family of DSP cores architected to combine vision, Radar, and AI processing in a single architecture.
- The silicon-proven cores provide scalable performance to cover a wide range of applications that combine vision processing, Radar/LiDAR processing, and AI inferencing to interpret their surroundings. These include automotive, robotics, surveillance, AR/VR, mobile devices, and smart homes.
-
Tensilica Vision Q7 DSP
- Doubles Vision and AI Performance for Automotive, AR/VR, Mobile and Surveillance Markets
-
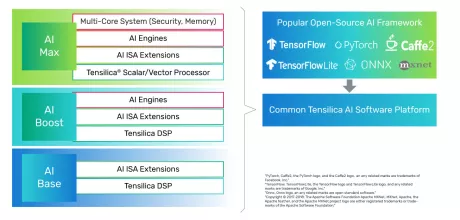
Tensilica DSP IP supports efficient AI/ML processing
- Powerful DSP Instruction Set Supporting AI/ML Operations.
- Mixed Workloads.
- Industry-Leading Performance and Power Efficiency.
- End-to-End Software Toolchain for All Markets and a Large Number of Frameworks.
-
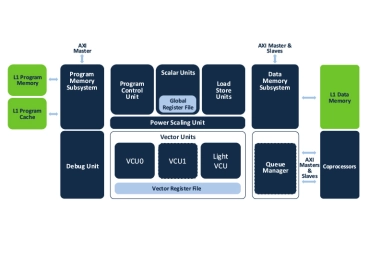
256 8-bit-MAC DSP core
- High performance vector signal processing and efficient control code processing
- 256 8-bit macs, or 128 16-bit macs, or 32-bit macs per cycle
- Flexible vector permute operations
- Maskable vector lanes
-
32 8-bit-MAC Vector DSP Core
- High performance vector signal processing and efficient control code processing
- 32 8-bit macs, or 16 16-bit macs, or 8 32-bit macs per cycle
- Flexible vector permute operations
- Maskable vector lanes
-
128 8-bit-MAC Vector DSP Core
- High performance vector signal processing and efficient control code processing
- 256 8-bit macs, or 128 16-bit macs, or 32-bit macs per cycle
- Flexible vector permute operations
- Maskable vector lanes
-
Tensilica AI Max - NNA 110 Single Core
- Scalable Design to Adapt to Various AI Workloads
- Efficient in Mapping State-of-the-Art DL/AI Workloads
- End-to-End Software Toolchain for All Markets and Large Number of Frameworks