Deep Learning IP
Filter
Compare
35
IP
from
19
vendors
(1
-
10)
-
High performance-efficient deep learning accelerator for edge and end-point inference
- Configurable MACs from 32 to 4096 (INT8)
- Maximum performance 8 TOPS at 1GHz
- Configurable local memory: 16KB to 4MB
-
Deep Learning Processor
- High performance: Whether it’s at the edge or in the cloud, videantis' processors provide the required performance.
- Scalable architecture: 1 to 1000+ cores address ultra-low cost to high-performance applications.
- Ultra-high MAC throughput: Each core computes a high number of MACs per cycle, resulting in an abundant amount of processing performance in multi-core systems.
-
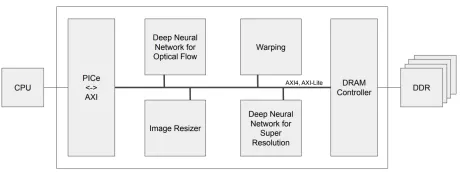
Deep Learning-based Video Super Resolution Accelerator IP
- DeepField-SR is a fixed functional hardware accelerator IP for FPGA and ASIC, offering the highest computational efficiency for Video Super Resolution.
- Based on proprietary AI models trained with real world video dataset and fusing spatio-temporal information in multiple frames, DeepField-SR produces superior high resolution video quality and upscales to fit lager displays.
-
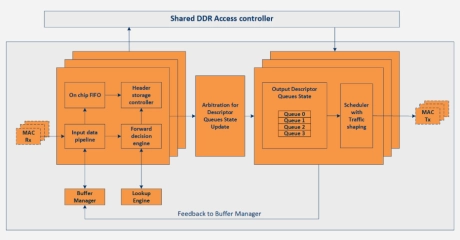
Deep Buffering Memory 1G Ethernet Switch
- The 1G deep buffering memory Ethernet Switch is an advanced Ethernet switching IP that supports buffering large amounts of data in external RAM.
- The non-blocking Ethernet switch IP core enables fine-grained traffic differentiation for rich implementations of packet prioritization, enabling per port and per queue shaping on egress ports.
-
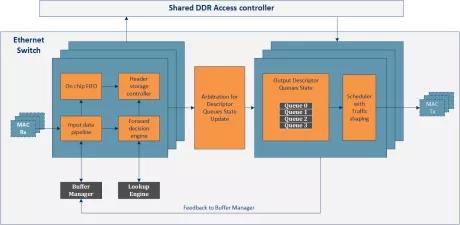
1G Deep Buffering Memory Ethernet Switch IP Core
- Delivers Performance
- Highly Configurable
- Easy to use
- Silicon Agnostic
-
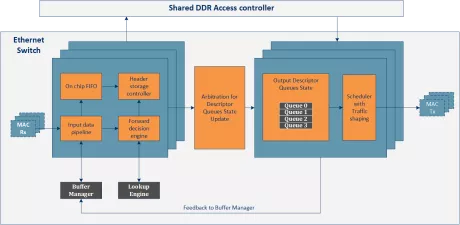
1G Deep Buffering Memory Ethernet Switch IP Core
- QoS features like classification, queuing and priorities included
- Automatic MAC address learning and aging
- Supports buffering of up to 128 MB in DDR
- Extensive statistic reporting
-
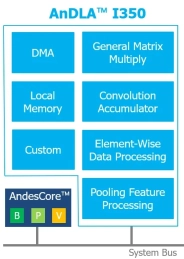
AI inference engine for real-time edge intelligence
- Flexible Models: Bring your physical AI application, open-source, or commercial model
- Easy Adoption: Based on open-specification RISC-V ISA for driving innovation and leveraging the broad community of open-source and commercial tools
- Scalable Design: Turnkey enablement for AI inference compute from 10’s to 1000’s of TOPS
-
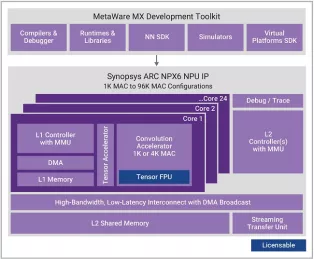
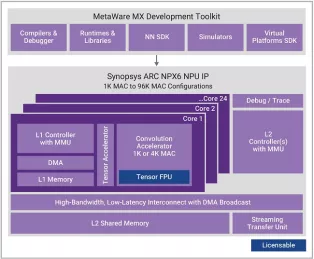
Optional extension of NPX6 NPU tensor operations to include floating-point support with BF16 or BF16+FP16
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
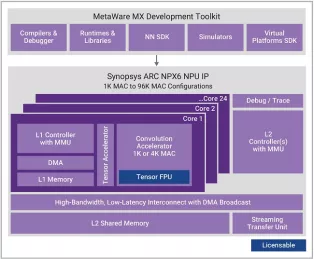
Enhanced Neural Processing Unit providing 98,304 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
Enhanced Neural Processing Unit providing 8,192 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator