AI DSP IP
Filter
Compare
58
IP
from
17
vendors
(1
-
10)
-
Vision AI DSP
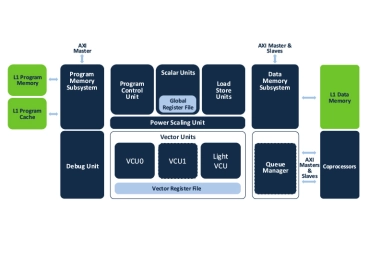
- Ceva-SensPro is a family of DSP cores architected to combine vision, Radar, and AI processing in a single architecture.
- The silicon-proven cores provide scalable performance to cover a wide range of applications that combine vision processing, Radar/LiDAR processing, and AI inferencing to interpret their surroundings. These include automotive, robotics, surveillance, AR/VR, mobile devices, and smart homes.
-
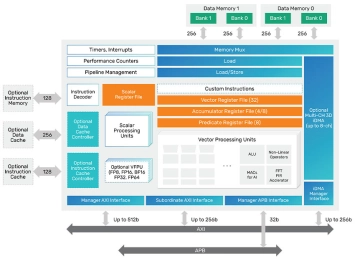
Tensilica DSP IP supports efficient AI/ML processing
- Powerful DSP Instruction Set Supporting AI/ML Operations.
- Mixed Workloads.
- Industry-Leading Performance and Power Efficiency.
- End-to-End Software Toolchain for All Markets and a Large Number of Frameworks.
-
HiFi iQ DSP
- 8X Increased AI Performance: Run the entire voice AI networks efficiently with configurable AI-MAC
- 2X Increased Raw Compute Performance: Wider SIMD allows more computations
- Expanded Data Type Support: Efficiently run cutting-edge voice AI models in FP8, BF16, and more
-
AI SDK for Ceva-NeuPro NPUs
- Ceva-NeuPro Studio is a comprehensive software development environment designed to streamline the development and deployment of AI models on the Ceva-NeuPro NPUs.
- It offers a suite of tools optimized for the Ceva NPU architectures, providing network optimization, graph compilation, simulation, and emulation, ensuring that developers can train, import, optimize, and deploy AI models with highest efficiency and precision.
-
5G IoT DSP
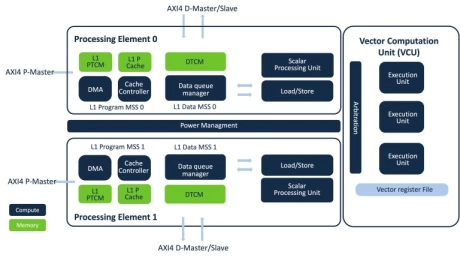
- The XC21 is the most efficient vector DSP core available today for communications applications.
- The XC21 DSP is designed for low-power, cost- and size-optimized cellular IoT modems, NTN VSAT terminals, eMBB and uRLLC applications.
- Ceva-XC21 offers scalable architecture and dual thread design with support for AI, addressing growing demand for smarter, yet more cost and power efficient cellular devices
-
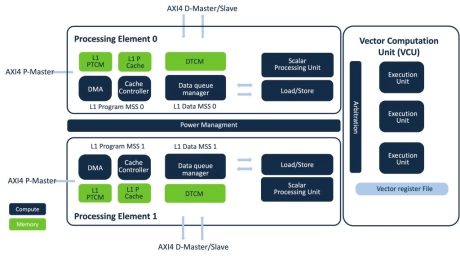
5G RAN DSP
- The XC23 is the most powerful DSP core available today for communications applications. The-XC23 offers scalable architecture and dual thread design with support for AI, addressing growing demand for smarter, more efficient wireless infrastructure
- Targeted for 5G and 5G-Advanced workloads, the XC23 has two independent execution threads and a dynamic scheduled vector-processor, providing not only unprecedented processing power but unprecedented utilization on real-world 5G multitasking workloads.
-
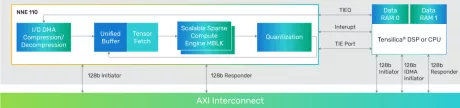
Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints
- Best-in-Class Energy
- Enables Compelling Use Cases and Advanced Concurrency
- Scalable IP for Various Workloads
-
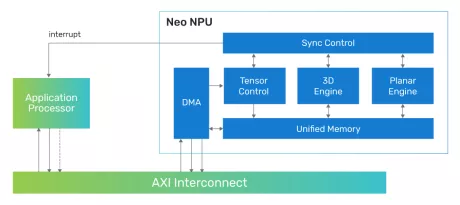
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
Tensilica Vision P6 DSP
- 1024/512b Load/Store capabilities
- 256 8-bit MAC
- 8/16/32-bit fixed-point processing
- Single-precision (FP32) and half-precision (FP16) floating-point processing
-
Tensilica Vision Q8 DSP
- 2048/1024b Load/Store capabilities
- 1024 8-bit MAC: 2X MAC capability versus Vision Q7 DSP
- 8/16/32-bit fixed-point processing
- Double-precision (FP64), single-precision (FP32), and half-precision (FP16) floating-point processing