Multi Chip, Multi Environment Simulation, Bringing Software Closer to Hardware and Saving Money
Bangalore India
Abstract :
One of the key problems faced while system simulating multiple chips from different vendors, is that all these chips might have been verified individually in different non compatible DV (Design Verification) environment. Hence, for system simulation, the individual DV environment cannot be reused easily or would need some expensive tools for inter operability.
The key challenge for disparate multi chip system simulation is to bring a standard interface which allows:
- Simulating multiple chips which were individually verified with different verification tools (vera, specman, C, verilog etc.)
- Simulating multiple chips which were individually verified with different simulators (NC verilog, vcs, modelsim etc.).
- c) Simulating multiple chips which were individually verified with version dependent tool (e.g. VCS and specman).
In this paper we present an approach which can overcome the above difficulties and leverage upon the existing DV environments without imposing restriction of any form. This approach uses socket as a vehicle for Inter Process Communication (IPC) between the disparate verification environments. This approach is currently being used in our environment and has already shown good results.
This paper will also discuss on some of the key challenges in designing the verification architecture for socket interface from a hardware perspective, like multiclock system architecture
Introduction
System simulating IP cores received from different vendors has always been challenging. The main issue is to come out with a DV environment which can leverage on the test bench set up and the test vectors provided by the vendor. To accomplish this we need to set up an environment which allows the individual cores to be run as a separate process and let them communicate.
The socket is a method for accomplishing inter- process communication (IPC). Stream sockets would suit best for our requirement, primarily because of the usage of the underlying TCP protocol which ensures that the data arrives sequentially and is error free.
A socket consists of two parts, a server and a client portion. The server portion opens a port and “listens” to any incoming connection on this port. The client tries to connect to a port on the server and once granted access a two way communication link is setup and message transaction can take place.
The main advantage of the socket architecture is that, it is independent of the environment to which they are attached, meaning the client and the server can be two completely independent systems and still can communicate to each other without imposing restriction of any kind.
In this paper standard BSD stream socket is used.
System Architecture
Background:
The challenge is to design a DV architecture which would allow co-simulation of a Host Chip with a PHY Chip. These chips were individually verified using different simulators, which were not compatible. Hence system simulation of these two chips posed problems, in the sense that there are no known tool which would allow their co-simulation. The only way to co-simulate them was to run these DV environments separately as two different processes and then, let these processes communicate the DUT (Design Under Test) pin values through a socket infrastructure.
In designing the socket architecture it is to be ensured that no messages were lost in communication.
Also it is necessary that the architecture maintained the clock to data relationship on the DUT pins. The architecture had to support the following DUT feature
• 5 Clock domains, fastest clock at 350 Mhz, and slowest at 50 Mhz. All clocks were independent ly generated by PLL having no phase relationship.
Architectural Overview
The interface was composed of two parts, a “C core “, providing the socket infrastructure and the message encoding/decoding logic and a “Verilog Connector Module (VCM)” which handles the PLI interface to verilog .
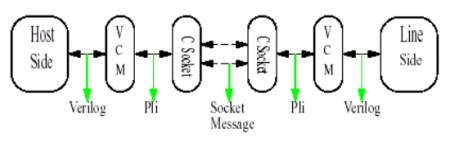
Figure 1: Architecture Setup
Verilog Connector Module (VCM): This module deals with the pli function calls between the “C Socket” and the verilog DUT. It initializes the socket and invokes the PLI system tasks.
C Socket Module: The C socket module has the encoding logic and socket core. The encoding logic encodes all the pin values. In order to transmit the value of a pin which can be one of ‘0’,’1’, ‘X’ or ‘Z’, two bits are needed, therefore for N pins, the socket message is (N * 2)/8 bytes long. Along with the connector data message additional control message is also sent. These control messages are used for end of simulation purposes.
Once the socket message is formed, it is sent across the socket. At the receiver the message is decoded and driven on the verilog pins by the pli library functions. The selection of the server (listening side) or client (connecting side) doesn’t really matter because once a socket is created, data flow is bidirectional.
Architectural Overview
While on the socket architecture, the following issues need to be taken care:
1. Number of DUT pins: The number of pins on the DUT interface decides the socket message length. If the amount of data to be transmitted per transaction is small, then in order to improve simulation time, TCP socket parameters should be set up accordingly so that it will not try to buffer the data before sending it (e.g., Nagle algorithm setting), which may result in slower simulation.
2. Number of clock domains: For single clock architecture, the socket consists of a single server and a single client. The message transactions will happen at the clock rate.
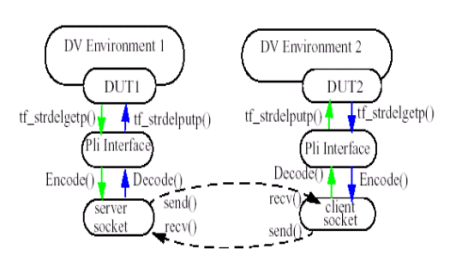
Figure 2: Single clock socket architecture
For multi clock domains, multiple architectures are possible, namely,
- Separate socket for each server - client
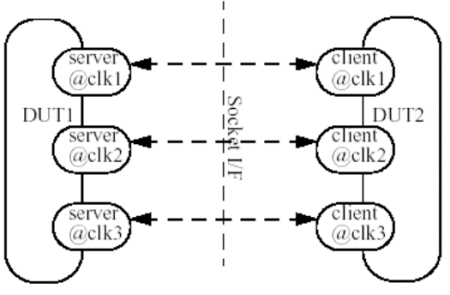
Figure 3: Multiple socket architecture
- Single server and multiple clients
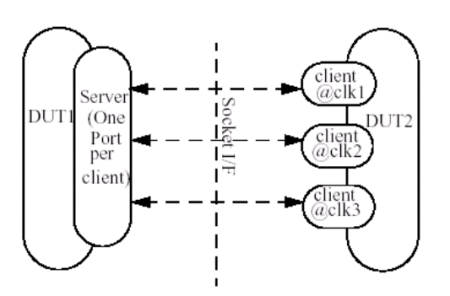
Figure 4: Single server, multiple client architecture
- Single socket (single server client pair) operation at high speed clock
The three architectures discussed have there own pros and cons which can be summarized in the following table

Simulation Flow
Before any transaction starts across the socket, it needs to be ensured that the server socket is spawned before the client can connect to it. The simulation flow can be depicted by the following flow diagram.
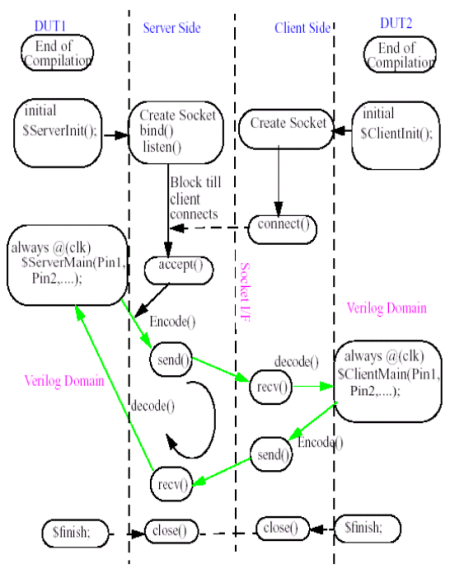
Figure 5: Simulation Flow
Server Side: After compilation, the server socket is setup (see the initial block on server side). The server blocks the simulation time, until the client connects to it. Once the client connection is established, the simulation time proceeds. The pin status on the server side DUT1 is sampled by the PLI, encoded and sent on to the socket interface (send()). It then waits for acknowledgement from the client, simulation time is stopped now. Once the acknowledgement is received (recv()), the received message is decoded and the input pins of the DUT1 are drive and the simulation time proceeds.
This process continues until end of simulation, when the socket connection is closed.
Client Side: After compilation, the client socket is set up. The client connects to the server, receives the message (recv()), decodes it and drives the input pins of the DUT2 through the PLI. The output pins are sampled by the PLI, encoded and send (send()) on the socket interface. At this point the simulation time is stopped until a new message is received on the socket interface.
This process continues until end of simulation, when the socket connection is closed.
Conclusion
By using sockets for Inter process communication, the existing DV environment of disparate systems can be leveraged. Also we can cut cost by saving on buying of expensive tools to co-simulate (for verilog / vhdl co-simulation there is no need to buy separate co-simulator.
It can be done by using the existing tools and use socket for inter process communication).
The main draw back of this type of simulation is that the simulation speed goes down because of socket message transactions. Also it takes some network bandwidth. Our implementation used high speed clock, socket architecture. This method is not the most efficient for it sends too many socket messages and slows down simulation. We need to move to the more efficient, single server, multiple client architecture.
Acknowledgements
I would like to thank sukalyan mukherjee for his valuable advice and support through this work. Thanks to senthil, mangesh and vinod for giving their valuable suggestions during the implementation.
Related Semiconductor IP
- RVA23, Multi-cluster, Hypervisor and Android
- 64 bit RISC-V Multicore Processor with 2048-bit VLEN and AMM
- NPU IP Core for Mobile
- V-by-One® HS plus Tx/Rx IP
- MSP7-32 MACsec IP core for FPGA or ASIC
Related White Papers
- Virtual Prototyping Environment for Multi-core SoC Hardware and Software Development
- NoCs and the transition to multi-die systems using chiplets
- A RISC-V Multicore and GPU SoC Platform with a Qualifiable Software Stack for Safety Critical Systems
- ipPROCESS: A Usage of an IP-core Development Process to Achieve Time-to-Market and Quality Assurance in a Multi Project Environment
Latest White Papers
- Concealable physical unclonable functions using vertical NAND flash memory
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions