High Level Synthesis of JPEG Application Engine
Sameer Arora, HCL Technologies Ltd.
Rajiv Kumar Gupta, HCL Technologies Ltd.
Anil Kamboj, HCL Technologies Ltd.
Noida India
Abstract:
High Level Synthesis (HLS) technology and tools are used to transform high level behavioral model written in C, to synthesizable hardware in RTL . We have evaluated one such commercial HLS tool to create JPEG encoder RTL straight from C algorithm within a very short design time. This paper discusses the steps involved in automatic “Algorithm to RTL” transformation and compares the results with RTL developed using traditional method.
I) INTRODUCTION
Advanced SoC for consumer devices such as cell phones, digital camera, DVD players are designed using platform based approach. An SoC can be partitioned into platform components and application engines. Platform components include system CPUs such as ARM or MIPS, memories, bus and external interfaces like USB.
Application engines are components like video codec, wireless modem or imaging pipeline. Platform components rarely change. It is the application engines that define the functionality of the product containing the SoC. For example, one cell phone may contain a GSM modem, 3.2 mega pixel camera and a camcorder. The other might have a WCDMA modem and 2 mega pixel camera and an FM radio.
These application engines vary in their architecture and their processing algorithms are constantly evolving. Designers often face the challenge of meeting tight design schedule and budget. Incorporating any algorithm change late in the design and re-integrating it with rest of the SoC becomes a bottleneck in the process.
A typical design process of an application engine includes first developing ANSI C or SystemC TLM models to support the different ESL design tasks like architecture exploration, embedded software development, and verification. Once the model is verified, the design is manually converted into RTL
description using hardware description language like Verilog. This manual conversion of the design from C/SystemC based model to HDL based RTL description is time consuming and error-prone.
To avoid “specification to RTL hand-off” problems, High Level Synthesis technology (HLS) [1] aimed at automating generation of synthesizable RTL from un-timed ANSI C algorithm has been introduced as a next big step in the VLSI design flow. Though this technology is still an active area of university and corporate research, there are already a few commercial HLS tools that has been used, evaluated and deployed by semiconductor companies.
To experimentally review the effectiveness of HLS flow in generating efficient hardware, improved Quality of Result (QOR) and reduced design time, we have adapted an HLS tool from Synfora named PICO (Program In – Chip Out). PICO is an eco-system of tools and IP that creates complex application engines from sequential C algorithm. PICO platform is used by us to create JPEG encoder hardware from existing C code.
Section II gives an overview of the HLS tools available in the market and reviews the underlying technology used in creating these powerful transformation engines. Section III discusses the baseline JPEG algorithm we have used for image compression. Section IV gives an overview of the design flow we have adapted using the PICO environment. Section V discusses the issue of rapid architecture exploration using the environment. Synthesis results and comparison of the netlist with third party IP core is shown in section VI. We conclude the paper by revisiting the evaluation goals we have set in context of the tool and HLS technology in the final section.
II) HIGH LEVEL SYNTHESIS
Commercial high level synthesis tools promise to generate correct-by-construction, high quality RTL 10-100x faster than manual design method. The tools enable the designer to pick the best architecture for given performance/area/power requirement and avoids the design errors introduced from hand coding the RTL description. HLS tools can be classified on the basis of input format [5], for example, if the input is C/C++ language then CatapultC from Mentor Graphics and PICO from Synfora can be used. For block diagram based, SynplifyDSP from Synplicity, and for SystemC based input, Cynthesizer from Forte Design Systems is usually used.
Tools used for transformation of C algorithm into RTL description employ highly advanced parallelizing compiler techniques [2], instruction scheduling algorithms, loop transformation techniques etc. to generate efficient hardware architecture. The idea is to exploit parallelism in C code at multiple levels (inter loop, intra loop and inter task etc) to find the best combination of performance, power and area for the hardware generated.
The synthesis engine associated with the tool takes system clock frequency and other information as input constrains along with the C code to generate hardware scheduler, instantiate hardware templates and inter connect them to give an RTL code in Verilog/VHDL that can be further synthesized into gate level net list using any third party synthesis tool. Most of the constructs used in ANSI C language can be implicitly transformed into hardware. For example an array can be typically synthesized into memory in most of the tools. Some hardware components like FIFO, multi-cycle multipliers are explicitly instantiated using constructs or API’s supported by the tool.
The HLS tools currently available enable RTL verification and hardware/software co-simulation by integrating third party RTL and SystemC simulator into the flow. It also generates standard interfaces to memory and bus for easy integration with rest of the SoC.
To adapt this new methodology and to integrate it into the existing ASIC/FPGA design flow, we have set some quantitative and qualitative evaluation goals. Conformance to these benchmarks gives a good understanding of the effectiveness and advantages of this method over existing design flow.
The quantitative goals are flexibility and speed to perform architecture exploration, comparison of area and speed against hand-coded design (third party IP), effectiveness of verification framework provided by the tool to meet our verification targets.
The qualitative goals are to understand the impact of HLS methodology on existing design flow, measure of productivity gain, tool effectiveness, learning curve and engineering skills required.
III) JPEG
We chose baseline sequential DCT JPEG compression [3] algorithm as an ideal candidate for this study. JPEG algorithm is moderately complex image compression technique which has pipeline of moderately complex computation blocks.
These blocks are:
- Discrete Cosine Transform (DCT)
- Quantization
- Entropy Encoding
Figure 1 shows the pipeline of JPEG blocks.
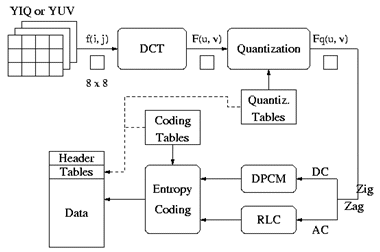
Figure 1. Baseline JPEG Encoder block diagram
Since a detailed treatment of the JPEG standard is outside the scope of this paper. A brief description of each block is given below [4]:
Discrete Cosine Transform:
This block converts each component (Y,U V) pixel of each 8 x 8 block to a frequency domain representation, using a normalized, two dimensional type-II discrete cosine transform (DCT). The resulting coefficients have a rather large value at the top-left corner of the 8x8 block. This is the DC coefficient. The remaining 63 coefficients are called the AC coefficients.
Quantization:
This step takes advantage of low sensitivity of human eye to high frequency brightness variation to greatly reduce the amount of information in the high frequency components. This is done by simply dividing each component in the frequency domain by a constant for that component, and then rounding to the nearest integer. This is the main lossy operation in the whole process.
Entropy Encoding:
Entropy coding is a special form of lossless data compression. It involves arranging the image components in a "zigzag" order employing run-length encoding (RLE) algorithm that groups similar frequencies together, inserting length coding zeros, and then using Huffman coding on what is left.
We started with the initial design specifications of JPEG encoder as:
- Max. image processing size 640 X 480
- Target Frequency 100 MHz
- Target Technology: 90 nm
To implement JPEG encoder in hardware, the C code of the application is first partitioned into non-programmable (hardware) and programmable (software) portions:
Compute intensive tasks of JPEG encoding kernel are the obvious candidates for implementation as non-programmable components. The driver code and pre-processing steps like color space transformation; downsampling and block splitting that can be run on programmable hardware or processor form the software portion.
Initial partitioning decision was based on profiling of the code using conventional software profiling tools like gprof.
A snapshot of profiling result is shown in table 1. The profiling result gives an idea of CPU intensive tasks used in JPEG encoding. Methods like writebits, writebytes are file I/O related functions that form part of the application software. It is worth noting here that functions like DCT, quantization, zigzag and Huffman blocks shows high CPU utilization and hence can be best implemented as non-programmable components to reduce processor load.
| % time | cumulative seconds | self seconds | self calls | total ms/call | ms/call | name |
| 50.00 | 0.01 | 0.01 | 19252 | 0.00 | 0.00 | writebits |
| 50.00 | 0.02 | 0.01 | 1152 | 0.01 | 0.01 | quantization |
| 0.00 | 0.02 | 0.00 | 7153 | 0.00 | 0.00 | writebyte |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | Code_DC |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | HuffmanCode |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | RLC |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | dct |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | dct_col |
| 0.00 | 0.02 | 0.00 | 1152 | 0.00 | 0.00 | dct_row |
Table 1: Snapshot of JPEG application profiling result
Once the code is partitioned, it is taken through HLS flow by instrumenting the C code with tool specific APIs and special constructs used to instantiate explicit hardware, to make the code synthesizable.
The tool transforms the code through a series of incremental steps that include preprocessing, linting, scheduling and synthesis to generate RTL architecture. At each step of transformation, simulation is done on intermediate representation to verify its functionality. The steps involved in the transformation are tool specific and may not be present in tools from other vendors.
The heart of RTL architecture generated by PICO is configurable Pipeline of Processor Arrays© (PPA) designed for compute-intensive C code. The PPA architecture is designed for efficient implementation of high performance processing pipelines, typically found, for example, in video, audio and imaging applications.
The PPA architecture comprises three levels of hierarchy:
i). Pipeline of Processing Arrays (PPA):
A PPA consists of a number of Processing Arrays (PA) connected to FIFOs, which are used for communicating data from one PA to the next. The timing controller coordinates the operations of all the PAs in the pipeline.
ii). Processing Array © (PA):
Each PA consists of one or more Processing Elements (PE) connected to each other using a nearest-neighbor interconnects. PAs incorporate local memories to store data locally. PICO supports both SRAM and fast registers for local storage.
iii).Processing Element© (PE):
Each PE contains a number of functional units such as adders and multipliers, load/store units etc.
The architecture generated by the tool is designed to support parallelism at all levels:
(i). Inter-task parallelism:
For example, one PA can start processing the next task in the JPEG pipeline while the other PA is executing an earlier task in the pipeline.
(ii). Intra-task parallelism: For example, once one
PA has completed part of a task; the other PA can start working on the task while the first PA is still completing it.
(iii). Iteration-level parallelism in a task:
Multiple iterations of a loop can execute in parallel on multiple PEs in a processing array.
(iv).Instruction-level parallelism within iteration:
Multiple operations can execute in parallel on Multiple functional units in a PE.
In order to leverage high degree of parallelism offered by the architecture described above, the C code has to be written as pipeline of function calls each having at least one for loop with fixed bounds. For example, one of the tasks in JPEG processing pipeline is Quantization as described in section III. The C code of quantization task can be coded as shown (fig.2)
void quantization (int imBlock[64], int QT[64])
{
long int values;
int index;
for (index =0; index<64; index++)
{
values = imBlock[index] * QT[index];
values = (values + 0x4000) >> 15;
}
Figure 2: sample C code of Quantization block
When this code is run through PICO tool, the for loop inside the task is mapped to one or more processing arrays(PAs) and hardware resources are allocated for each operation. In this case , it is one multiplier, an adder and a shifter. Resource allocation is done to leverage multiple level of parallelism so that the design meets frequency and throughput constraints specified by the designer.
The process of C code profiling, partitioning and synthesis is repeated more than once to find the best combination of performance, area and power. Initially, Huffman encoding block was implemented in software, but as we kept on partitioning and mapping more functionality into the hardware, we found that the tool performed aggressive architecture optimization to allow the this block to be synthesized into RTL without slowing down the system clock, although there was some increase in overall gate count.
Repartitioning the code and comparison of synthesis result took very little time compared to manual method. Taking repartitioning decisions in traditional method is not easy as it often entails rewriting the complete RTL, with significant penalty on design time. HLS technique has this advantage of making iterative partitioning decision and implementation of the design in a matter of few days.
The tool also generates driver code that can be cross- compiled for the target host. The interfaces of the PPA generated are usually standard interfaces for seamless integration with the rest of the SoC.
V) Architecture exploration:
Reduction in design time of hardware architecture using this method has enabled us to spend considerable time on architecture exploration to find the best alternative for given speed and throughput constraint.
The tool supports architecture exploration by varying frequency and parameters such as number of clock cycles needed to execute the program and maximizing number of task overlaps. By varying these parameters, we got numerous successful exploration points in a single simulation run in a matter of few hours. The graph (Fig. 3) shows the variation in the throughput (No. of tasks run per second) achieved while varying frequency from 200 MHz to 500 MHz with a step size of 50 MHz.

Figure 3: Frequency Vs throughput graph showing design points having high throughput at higher frequency
Cost versus frequency graph (Fig. 4) is quite intuitive, one can see an obvious increase in cost at higher frequency and throughput as the compiler associated with the tool tries to allocate more resources in order to parallelize tasks for maximizing throughput.
The gate count reported by the tool is very pessimistic as the HLS tool does not predict the optimization performed by third party back end synthesis tool like Synopsys’ DC Compiler©. Nevertheless, the cost estimated is useful for comparing several versions of the design. It is always good to synthesize the RTL to make final comparison.

Figure 4: frequency vs. cost graph
VI). Result:
We synthesized JPEG application engine running at a frequency of 200 MHz with overall gate count of 58K using TSMC 90 nm ASIC library.
Table 2 gives a comparison between our designs synthesized using HLS tool and a third party IP designed using traditional method.
| Synopsys Area | Target Technology | Frequency (MHZ) | Timing met? | |
| HLS Design | 58 K | 90 nm | 200 | Yes |
| Hand Coded design | 64K | 180 nm | 142 | Yes |
Table 2: Comparison of HLS based design with third party JPEG IP of similar complexity
In section II, we had set some quantitative and qualitative evaluation goals to find the effectiveness of this new technique of chip design and to answer certain tool deployment issues a chip design company faces when it comes to real design tape-out
We have used this tool for generating hardware architectures for imaging as well as data encryption applications like AES and SHA-256. We have achieved considerable productivity gains and got a similar speed and area report compared to hand coded design. We have not done power estimation of the RTL generated using HLS tool. It is part of our future work.
The tool does black box verification by comparing output of the simulation run with golden output at every stage of transformation. One of the major problems in coverage based verification is to know the answer to the question: “When is verification done?” HLS technique has an inherent advantage that the code coverage process is most efficient if the user assures that the C-code has reasonably complete coverage of the application.
Working at the C-code level is also the most efficient way to assure that the resulting RTL code will be covered. We are working on development of effective verification plan to find out how fast verification targets can be met by improving the coverage at the algorithmic level.
We could come out with a working JPEG design within 4 months of start of project; this duration also includes tool learning and code instrumentation. However, we have not taken in consideration time to write the application in C. The tool we have used seamlessly fits in the existing design flow, as it generates RTL synthesis scripts to support back-end synthesis on most commercial synthesis tools like DC Compiler© from Synopsys and RTL Compiler© by Cadence.
The issue we faced using the tool is the effectiveness in carrying out late design changes (ECO) at RTL level. In the context of HLS tools, this means that users need a good understanding of the RTL created by the tool.
Instead of tweaking the code at RTL level, we found it safe to modify the C code for any design changes
VII) Conclusion:
High level Synthesis technology apart from reducing design time, has abstracted away architecture details from the designer and has broken down the invisible boundary between a software engineer involved in writing a behavioral model and an hardware engineer developing the RTL of the model. However, no matter how good the behavioral model, it is no substitute for a hardware engineer’s intuitions regarding the top level architecture and design choices at the RTL level.
This paper has introduced high level synthesis concept and methodology we have used to synthesize JPEG encoder engine. High level synthesis technology is enabling semiconductor companies to significantly reduce RTL design time and cost.
It is clear that high level synthesis technology will form an integral part of EDA tool eco-system used for SoC design of the future. What remains to be seen is whether it can completely replace the role of RTL designer and bring us a step closer to realization of “Specification to Silicon” dream.
VIII). References
[1] Arvind, Rishiyur Nikhil, Daniel Rosenband, Nirav Dave. High Level Synthesis: An essential ingredient for designing complex ASICs. Proceedings of the International Conference on Computer Aided Design (ICCAD 2004), San Jose, California.
[2] www.synfora.com
[3] www.jpeg.org
[4] http://en.wikipedia.org/wiki/JPEG#Encoding
[5] Behavioral Synthesis Tools Match Different
Needs, Nikkei Electronics Asia -- October 2007, Nikkei Business Publications, Inc, http://techon.nikkeibp.co.jp/article/HONSHI/20070926/139718/
{kind=link}
Related Semiconductor IP
- JPEG XL Encoder
- High-Speed JPEG Video Encoder
- TicoXS | JPEG XS 4K Encoder / Decoder IP-core
- JPEG XS Codec with Flawless Imaging - Max res: 7680x4320 - Max fps: 60
- JPEG encoder
Related Articles
- Application engine synthesis offers new design approach
- H.264 encoder design using Application Engine Synthesis
- Reconfiguring Design -> FPGAs speed audio application development
- Soc Design -> Soft design for cryptographic engine
Latest Articles
- Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
- A Scalable Open-Source QEC System with Sub-Microsecond Decoding-Feedback Latency
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS
- A Persistent-State Dataflow Accelerator for Memory-Bound Linear Attention Decode on FPGA