Hybrid Hardware Architecture for Low Complexity Motion Estimation Algorithm
By Muhammad Aslam, Anıl Çelebi (Kocaeli University)
Abstract:
Nowadays hybrid hardware architecture (HHA) becomes increasingly popular in embedded systems (ES). In this paper HHA is presented for low bit depth motion estimation (ME) algorithm. Intellectual property (IP) core is designed for ME algorithm by using field programmable gate array (FPGA) and this IP is integrated with processor system (PS) to investigate its performance in an ES. Designed ME based IP has data bus of size 32bits and is working properly up to 200 MHz. Experiments show that the HHA is integrated successfully and gives expected results in real time.
Keywords—Intellectual property, hybrid hardware architecture, motion estimation, direct memory access, embedded system.
1. Introduction:
Embedded systems (ES) can be seen everywhere in daily life. Generally, they are application specific such as printer, mobile phone, TV, camera etc. Video encoder is also a typical ES which compresses capturing videos and reduces the size of video data considerably. There are different kinds of redundancies in captured videos; these redundancies are exploited by video encoder to reduce the size of capturing video considerably. ME is one of the most important parts of a typical video encoder. Block based motion estimation (BME) is used to remove the temporal redundancy between video frames. Generally, in BME current video frame is divided into non overlapping blocks and each current block (CB) is searched within the search area (SA) which is extracted from reference frame. In exhaustive search motion estimation (ESME) algorithm, all points within predefined search range are exercised. ESME is computationally very expensive. Different kind of ME algorithm are presented to decrease the computational complexity of ESME. Three point search based and hexagonal shaped based ME are presented in [1] and [2] respectively.
These kind of ME algorithms decrease the computation complexity of ME by decreasing the number of search points but this kind of algorithms also decrease the ME accuracy considerably. In [3], early termination method is presented to sustain the ME accuracy as well as to decrease the computational load of ME. Another approach to decrease the complexity of ME is by using few bit planes by discarding the remaining bit planes within a video frame.
In [4] and [5], one bit plane based ME called one-bit transform (1BT) based ME and 2 bit plane based ME called two-bit transform (2-BT) based ME are presented for ME respectively. 2-BT base ME produces more accurate results but computationally complex as compared to 1BT based ME. In [6], constrained mask is used along with 1BT (C-IBT). C-1BT based ME has better performance as well as low computational load than 2-BT based ME because additional cost of constrained mask is quite low compared to 2-BT. 3 bit plane are employed in [7] for ME has better results as copmpared to previously presented low complexity ME algorithms. Several hardware architectures are also proposed for low bit depth based ME [7-11]. Diamond search and hexagonal search are presented for 1BT based ME and C-1BT based ME in [12] and [13] respectively. Early termination approaches are exploited for 1BT and 2BT based ME in [14] and [15] respectively.
A typical ES has processor, memory unit and inputs/outputs (IOs). Processor is the brain that control the entire ES. Memory supports the processor by holding data temporaily or permanentaly. IOs are used to interact with external world. Sometimes single processor is not enough to meet all requirements. Therefore some other devices such as FGPA or application specific integerated circuit (ASIC) are embedded with processor to meet the given requirements. This kind of architecture is called hybird architecture and this architecture becomes increasingly popular. Typical hybrid architecture for embedded system is shown in Figure 1.
In this paper, HHA for low compexity ME algorithm introduced in [16] is presented. Typical hybrid architecture shown in Figure 1 is impelmented with ME algorithm proposed in [16].
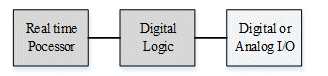
Figure 1 Typical hybrid hardware architecture within embedded system.
2. Proposed hybrid architecture:
Proposed HHA for ME algorithm proposed in [16] is shown in Figure 2. There are mainly three parts in this hybrid architecture; real time processor system, FPGA and display unit. Real time processor has processor system (PS) that sends current and reference pixels data to FPGA. FPGA has direct memory access (DMA) IP, custom IP that collectively receive data from PS and generate motion vectors (MV) and number of non-matching pixel (NNMP) values. Display unit mimics digital outputs and displays NNMP values and MV visually. Although display unit is also implemented in FPGA but it is shown separately in Figure 2. This is just to realize a typical HHA shown in Figure 1.
2.1. Processor system:
ARM processor is utilized in the proposed hybrid architecture. ARM processor in ZYNQ series FPGAs has High speed port (HP) and low speed port called general port (GP). HP and GP are used for high data rates and low data rate devices respectively. In proposed HHA, DMA IP is configured by using DMA controller signal. DMA IP configuration needs low data rate, therefore GP port is exploited here. In real world, video streaming needs high data rate. This is achieved in the proposed design by using HP port. HP port is used to send current and reference block pixels to the custom IP through DMA IP.
2.2. DMA IP:
DMA IP is utilized as interconnection between PS and custom IP. The main function of this IP is to provide synchronization between PS and custom IP. DMA IP, after its configuration through DMA controller, receives current and reference frame pixels and converts them to a specific format on which custom IP is working.
2.3. Custom IP:
Custom IP has mainly two submodules; memory management and ME algorithm. PS and DMA IP are working on standard protocol. For example in proposed HHA, they have data bus of size 32 bits. ME architecture presented in [16] has data bus of size 144 bits. Memory management unit receives pixel stream via DMA IP, separate it into current and reference frame pixels and then converts into data of width 144 bits before sending it to next submodule. In addition memory management also provides synchronization for ME engine. ME engine submodule mainly contains ME algorithm presented in [16]. It receives data from memory management and generates MV and NNMP values at the output.
2.4. Display Unit:
Display unit is used to display the generated NNMP values and MVs in visual form. Two different IPs are used in this unit; virtual input output (VIO) IP and integrated logic analyzer (ILA) IP. VIO IP is utilized to display MVs. Since VIO IP generally displays the last generated data, VIO IP is not suitable to display NNMP values because ME algorithm proposed in [16] generates 1089 different NNMP values for each 16×16 current block. ILA IP is exploited here to display each and every generated NNMP value.
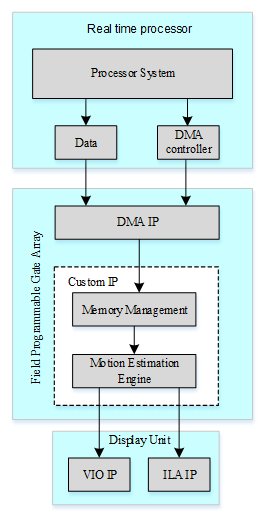
Figure 2 Proposed hybrid architecture
3. Implementation results:
Zynq series FPGA is utilized for implementation of proposed HHA. Zynq series FPGA has two part; PS and programmable logic (PL). Custom IP, ILA IP, VIO IP and DMA IP are implemented in PL part of Zynq series FPGA and PS part of Zynq series FPGA is used to configure and send current and reference block pixels to DMA IP. Implemented diagram of proposed hybrid architecture is shown in Figure 3.
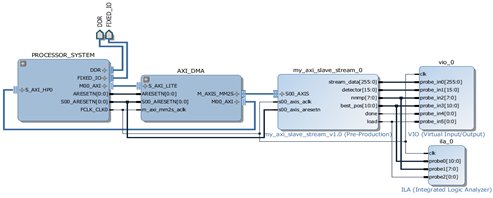
Figure 3 implementation of Integrated system

Figure 4 VIO output
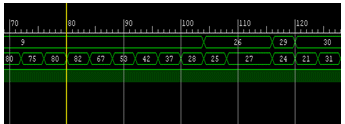
Figure 5 ILA output
4. Conclusion:
In this paper, novel HHA for low complexity ME proposed in [16] is presented the first time in the literature. An IP for ME algorithm presented in [16] is designed in FPGA. Since in real world, ME IP is embedded in a typical video encoder therefore this IP is integrated with the PS and performance of this ME IP is measured in the proposed embedded system. Experiment results show that this IP can be integrated easily in any embedded system. In addition ILA IP and VIO IP are exploited to see the performance of the ME IP visually. Designed ME based IP is working on data bus of size 32bits at maximum 200 MHz successfully. Since this IP is self-synchronized via memory management unit which is present inside it, this IP can be integrated with any system that has data bus of size 32 bits without any extra setting.
Acknowledgment:
This work is supported by TUBİTAK under project number 115E921. I would like to convey my heartiest thanks to Oğuzhan Urhan and Ali Can Karaca for their invaluable advices and encouragement.
References:
[1] T. Koga, K. Iinuma, A. Hirano, Y. Iijima, and T. Ishiguro, “Motion compensated interframe coding for video conferencing,” in: Proceedings of the National Telecommunications Conference, New Orleans, November 29–December 3. 1981,pp. G5.3.1–G5.3.5.
[2] S. Zhu and K.K. Ma, “A New Diamond Search Algorithm for Fast Block-Matching Motion Estimation,” IEEE Trans. Image Process., vol. 9, pp. 287-290, 2000.
[3] C. Shen, S. Li, “Search centre prediction-based partial distortion search motion estimation algorithm,” Electronics Letters, vol. 43, pp. 213-214, 2007.
[4] B. Natarajan, V. Bhaskaran, and K. Konstantinides, “Low-complexity block-based motion estimation via one-bit transforms,” IEEE Trans. Circuit Syst. Video Technol., vol. 7, pp. 702-706, 1997.
[5] A. Ertürk and S. Ertürk, “Two-Bit Transform for Binary Block Motion Estimation,” IEEE Trans. Circuit Syst. Video Technol., vol. 15, pp. 938- 946, 2005.
[6] O. Urhan and S. Ertürk, “Constrained one-bit transform for low-complexity block motion estimation,” IEEE Trans. Circuits and Syst. Video Technol., vol. 17, pp. 478-482, April 2007.
[7] A. Çelebi, O. Akbulut, O. Urhan, and S. Ertürk, “Truncated Gray-Coded Bit-Plane Matching Based Motion Estimation and its Hardware Architecture,” IEEE Trans. Consumer Electron., vol. 55, pp. 1530-1536, 2009.
[8] A. Çelebi, O. Akbulut, O. Urhan, I. Hamzaoğlu, S.Ertürk, “An All Binary Sub-Pixel Motion Estimation Approach and its Hardware Architecture,” IEEE Trans. Consumer Electron., vol. 54, no. 4, 2008.
[9] A. Akın, Y. Doğan, İ. Hamzaoğlu, “High Performance Hardware Architectures for One Bit Transform Based Motion Estimation,” IEEE Trans. Consumer Electron., vol. 55, pp. 941-949, 2009.
[10] A. Akın, G. Sayılar, I. Hamzaoğlu, “High Performance Hardware Architectures for One Bit Transform Based Single and Multiple Reference Frame Motion Estimation,” IEEE Trans. Consumer Electron., vol. 56, pp. 1144-1152, 2010.
[11] A. Çelebi, H. J. Lee, S. Ertürk, "Bit Plane Matching Based Variable Block Size Motion Estimation Method and Its Hardware Architecture," IEEE Trans. Consumer Electron., vol. 56, pp. 1625-1633, 2010.
[12] E.S. Lee, O. Urhan, T.G. Chang, “Multiplication-free one-bit transform and diamond search combination for fast binary block motion estimation,” in: Proc. IEEE 15th Conf. on Signal Processing and Communications Applications, Eskişehir, Turkey, June 11-13. 2007, pp. 430-433.
[13] O. Urhan, “Constrained one-bit transform based motion estimation using predictive hexagonal pattern,” Journal of Electron. Imaging, vol. 61, Article ID: 033019, 2007.
[14] H. Lee, J. Jeong, “Early termination scheme for binary block motion estimation,” IEEE Trans. Consumer Electron., vol. 53, pp. 1682-1686, 2007.
[15] H. Lee, S. Jin, J. Jeong, “Early termination algorithm for 2BT block motion estimation,” Electronics Lett., vol. 45, pp. 403-405, 2009.
[16] S. Yavuz, A. Çelebi, M. Aslam, O. Urhan, “Selective Gray-Coded Bit-Plane Based Low-Complexity Motion Estimation and its Hardware Architecture,” IEEE Transactions on Consumer Electronics, Vol. 62, No. 1, pp. 76-84, Feb. 2016.
About Authors:
 Muhammad Aslam was born in Bahawalpur, Pakistan. He received the B.Sc., degree in electronics engineering from International Islamic University, Islamabad, Pakistan, in 2014. Since 2015 he has been with the Department of Electronics and Telecommunications Engineering, University of Kocaeli, Turkey, where he is student of master degree. His current research interests include video coding/motion estimation: algorithm and implementation using FPGA.
Muhammad Aslam was born in Bahawalpur, Pakistan. He received the B.Sc., degree in electronics engineering from International Islamic University, Islamabad, Pakistan, in 2014. Since 2015 he has been with the Department of Electronics and Telecommunications Engineering, University of Kocaeli, Turkey, where he is student of master degree. His current research interests include video coding/motion estimation: algorithm and implementation using FPGA.
 Anıl Çelebi (S’00, M’09) was born in Ordu, Turkey. He received the B.Sc., M.Sc. and Ph.D. degrees in electronics and communication engineering from Kocaeli University, Kocaeli, Turkey, in 2002, 2005, and 2008, respectively. Since 2002 he has been with the Department of Electronics and Telecommunications Engineering, University of Kocaeli, Turkey, where he is currently working as an Assistant Professor. He worked as a BK21 Post-Doctoral Research fellow at the School of Electrical Engineering and Computer Science at Seoul National University, Korea between April - July 2009. His research interests include very large scale integration (VLSI) design and implementation for analog/mixed signal systems, image processing and video coding systems.
Anıl Çelebi (S’00, M’09) was born in Ordu, Turkey. He received the B.Sc., M.Sc. and Ph.D. degrees in electronics and communication engineering from Kocaeli University, Kocaeli, Turkey, in 2002, 2005, and 2008, respectively. Since 2002 he has been with the Department of Electronics and Telecommunications Engineering, University of Kocaeli, Turkey, where he is currently working as an Assistant Professor. He worked as a BK21 Post-Doctoral Research fellow at the School of Electrical Engineering and Computer Science at Seoul National University, Korea between April - July 2009. His research interests include very large scale integration (VLSI) design and implementation for analog/mixed signal systems, image processing and video coding systems.
Related Semiconductor IP
- NPU IP Core for Mobile
- V-by-One® HS plus Tx/Rx IP
- MSP7-32 MACsec IP core for FPGA or ASIC
- 100G / 200G / 400G / 800G / 1.6T MACsec
- 32 bit RISC-V Multicore Processor with 256-bit VLEN and AMM
Related White Papers
- A Low Complexity Parallel Architecture of Turbo Decoder Based on QPP Interleaver for 3GPP-LTE/LTE-A
- Reusable Verification Model for Motion estimation Algorithm
- How hybrid Structured ASICs provide low cost solutions for mid-range applications
- Unite algorithm and hardware design flows
Latest White Papers
- Concealable physical unclonable functions using vertical NAND flash memory
- Ramping Up Open-Source RISC-V Cores: Assessing the Energy Efficiency of Superscalar, Out-of-Order Execution
- Transition Fixes in 3nm Multi-Voltage SoC Design
- CXL Topology-Aware and Expander-Driven Prefetching: Unlocking SSD Performance
- Breaking the Memory Bandwidth Boundary. GDDR7 IP Design Challenges & Solutions