Flexible Embedded Processors for Developing Multi-Standard OFDM Broadcast Receivers
Abstract
In this paper we present a set of embedded digital signal processors to build a programmable OFDM receiver that can address a variety of broadcast formats as used for both digital television and digital radio in multiple geographic regions. A programmable solution is desirable for these applications, in order to improve time to market for emerging standards, as well as to reduce the cost of maintaining product lines for multiple geographic regions. While today ASIC solutions are commonplace, we describe in this paper how a set of specialized, embedded programmable digital signal processors can compose a practical system with respect to both silicon area and power consumption. By this approach, we achieve a high degree of programmability at the cost level comparable to ASIC solutions.
I. INTRODUCTION
In this paper we present a set of embedded digital signal processors that can be integrated on a single IC to realize a programmable system for developing OFDM receivers. In order to achieve a practical system with respect to both silicon area and power, processors were specialized in terms of functionality, data communication, and precision according to their role in the receiver system. The processors are programmed using a restricted form of ANSI-c, and easily integrate with common system-on-chip platforms. Thanks to Silicon Hive’s capability to design and automatically generate processors along with their compatible c-based compilers, the processors can be further specialized for different tradeoffs between flexibility, cost, and power consumption. In this way systems for consumer price points can be developed if required.
The focus of this paper will be the case study of a system for OFDM broadcast receivers, including system considerations used to develop the initial processor set, and issues in hardware and software development. A programmable OFDM receiver can address most broadcast formats that are used for both digital television and digital radio in multiple geographic regions. DVB-T in Europe [1], ISDB-T in Japan [2], and DAB [3] are examples.
A programmable solution is interesting for these applications in order improve time to market for emerging standards, as well as to reduce the cost of maintaining product lines for multiple geographic regions. ASIC solutions are commonplace, however, due to overriding concerns for silicon area, cost, and power consumption.
A practical programmable solution can be achieved for these OFDM systems by partitioning their functionality according to processing requirements. If processors can be specialized to each partition, then processing and area efficiency can be significantly improved with respect to implementation on general purpose DSPs or FPGAs. In this case three main processors are developed. The first includes the BRESCA stream processor for sample-by-sample processing common to the time domain portion of each OFDM system. Another processor, the AVISPA, is specialized for OFDM demodulation and frequency-domain processing. Finally, a forward error correction suite (MOUSTIQUE iFEC, AVISPA FEC, MOUSTIQUE oFEC) handles metric processing, Viterbi decoding, Reed-Solomon decoding, and byte processing.
Silicon Hive, a fully owned business of Philips Electronics N.V., licenses these processors which enable its customers to rapidly bring new OFDM receiver products to market.
The first version of each core is designed with a high degree of flexibility for the first implementation of DVB-T software. Benchmarks from these results are presented, including physical design results. Finally, scenarios will also be discussed that reduce processor flexibility in order to minimize silicon area and power consumption.
II. OFDM SYSTEM CONSIDERATIONS
The processor set is meant to take over the digital baseband signal processing tasks of the OFDM broadcast receiver. The design goal is to support multiple OFDM standards. Amongst them are the European DVB-T standard, the Japanese ISDB-T standard and the DAB digital radio standard.
Besides the differences in the standards, all OFDM based broadcast standards follow to some extend the receiver block diagram for the OFDM reception as given in Figure 1.
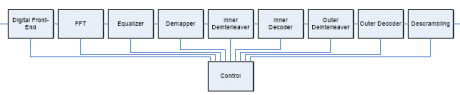
Figure 1
The standards differ in the details of the blocks in the diagram. Sometimes blocks are not present or in a different order then showed in figure 1. So although all OFDM standard have a lot in common, the entire processing chain can differ significantly.
The potential for efficient hardware reuse in a multi standard OFDM receiver implementation is high due to the resemblance of the standards. The feasibility of such reuse in classical hard-wired solutions however typically is low due to the large amount of effort required to create these multi standard hard-wired solutions.
Flexible software programmable processors do allow for easier reuse of hardware in multi standard systems, simply by means of a different program running on the same processor.
III. OFDM PROCESSOR DESIGN
A. ARCHITECTURAL CONSIDERATIONS
In a traditional ASIC design approach in a first step the OFDM signal processing chain is decomposed into its key functional components. For each of them, processing rates, input clock, memory requirements, and data throughput are determined. The actual design on register transfer level (RTL) is then performed with applying best design practices. In terms of silicon area and power consumption, typically the ASIC solution represents the benchmark against which alternative solutions like DSP or FPGA based implementations are measured.
Regarding flexibility, however, ASIC solutions have two relevant disadvantages. In order to make the design configurable towards multiple standards, either a lot of design effort must be spent on efficient reuse of hardware blocks or both standards must be implemented separately, a significant cost disadvantage.
The situation becomes even worse when there are modifications in the standards as it is typical for emerging applications. It is almost impossible to cope with these changes without a costly re-design cycle.
The situation is different for the approaches based on the specialized signal processors as it will be described in more detail throughout the rest of this paper. Without doubt, the degree of flexibility of a generic processor is almost unlimited and hard to beat by programmable ASICs. The usual counter argument, however, concerns the silicon area and power consumption of generic processors, which aim to provide ASIC like performance.
The proposed Silicon Hive [4] set of flexible, autonomous processors thus is focused to overcome this dilemma. How this is achieved is explained below.
First of all the Silicon Hive processors are specialized processors in contrast to general purpose DSPs. The specialization makes them more efficient at performing certain tasks. They will be less power consuming and smaller. This requires however the definition of these specialized processors.
With regard to the OFDM baseband receiver, architectural criteria to decide on the number and characteristics of the processors are:
- data flow characteristic, i.e., processor operates on streaming data or blocks of data
- data rate requirements
- data type, precision
- minimizing interface signals between processors
The table below provides the analysis results in relation to the generic block diagram presented in figure 1. Here the DVB-T application is used as an example.
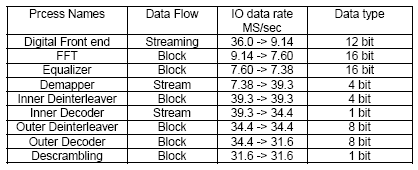
The above mentioned analysis resulted in the creation of 5 specialized cores. First there is the BRESCA core that handles the 12 bit streaming digital front-end. Then there is the AVISPA that handles the 16 bit block based FFT and Equalizer. The 4 bit demapper and inner deinterleaver are done on the Moustique iFEC core. The inner decoder (Viterbi decoder) is done the the AVISPA FEC core. Finally the outer deinterleaver, outer decoder (Reed Solomon) and descrambling is done on the bit/byte based Moustique oFEC core.
Figure 2 shows the mapping of DTV receiver functions to processors.
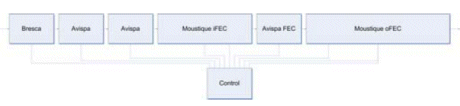
Figure 2
B. PROCESSOR DESIGN FLOW
Silicon Hive processor design relies on the generation of the dedicated RTL code based on an abstract description of the processor functionality. From the same abstract description the necessary compatible software development tools like compiler, scheduler, simulator and assembler are generated. Note the contrast to a pure ASIC design, for which the synthesizable RTL hardware model is sufficient: in the Silicon Hive flow the design of RTL, software and tools are integral.
Silicon Hive has developed a proprietary internal design methodology and toolset to enable automatic instantiation of an architecture template [5,6]. This template allows for the abstract description of a processor in terms of instruction set, interconnect, register files, memories, caches, FIFOs and IO to the outside.
Many design choices can be evaluated using the hardware/software co-design approach. Cycles of processor generation, application code compilation and evaluation, re-architecting and re-evaluation are very short. The number of issue slots, register files, the interconnect between execution units and register files, the instruction set (including SIMD instructions and application-specific operations), number, connection and porting of local memories can all be chosen at design time. Using this iterative approach, an optimum can be achieved for a particular target application.
Having said this, processor design reduces to writing the abstract processor model for each of the OFDM processors. Here, general arithmetic operations are mapped on standard functional unit like an ALU. In contrast to a standard DSP, however, the operation set is enriched by application specific operations. For example there are Galois field arithmetic functional units for the Moustique oFEC processor for Reed Solomon decoding. Thus, each processor consists of a limited number of standard digital signal processing operations plus, when required, very dedicated and specialized operations.
Regardless of the amount of specific operations the hardware design flow as explained above is applicable. In fact, updating the RTL processor model when one more functional unit has been added is a process which only needs minutes. The same short design cycle holds for aspects that are described in the architecture template.
IV. INTEGRATION ASPECTS
A. HARDWARE INTEGRATION
In the previous chapter we explained how the OFDM system was decomposed into a set of Silicon Hive processors. In this chapter now we describe the integration into one single IC, which then becomes available for the end user as programmable, multi-processor OFDM receiver chip.
Key integration tasks are amongst others the specification and implementation of - An on-chip communication network infrastructure
- A communication protocol between Silicon Hive processors over clock boundaries, which handles the timely exchange of processed data to avoid overall system stall
- The exchange of information between the individual Silicon Hive processor and the host processor
To ease the integration of Silicon Hive processors on IC chip level certain interface features are inherent to the Silicon Hive processors. There is one common set of interface signals, i.e., ports, on processor level. One common communication protocol handles the exchange of data between Silicon Hive signal processors. It consists of FIFO (first in, first out) memories and a token-based protocol.
The overall on-chip communication network applies a multi-layer bus for smooth integration of the processors onto chip-level.
The figure below shows as an example how the AVISPA core communicates to the next MOUSTIQUE iFEC core. The software task on AVISPA exchanges tokens with the task running on MOUSTIQUE iFEC. The data itself is stored by the task running on AVISPA in the memory of the next processor.
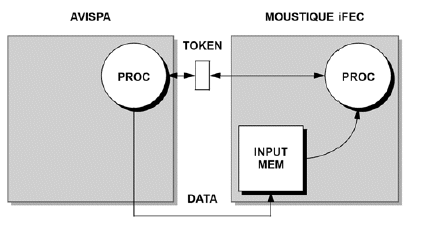
The protocol is depicted below.
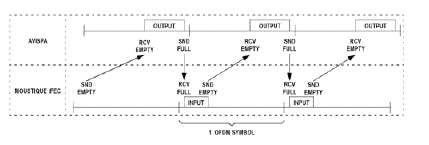
By applying these concepts, the infrastructure overhead in terms of silicon area is kept at minimum.
B. SOFTWARE INTEGRATION
In order to efficiently use the set of embedded digital signal processors for developing OFDM receivers, a number of programming concepts have been implemented.
- shared memories, i.e., one address mapping on chip level such that the HOST program sees all memories in its mapping table
- one common application programming interface (API) valid for each of the processors
The API significantly simplifies the programming on system level, which typically is performed on the HOST. With supplying a processor independent set of instructions and macros for downloading program code on the processor, for starting and stopping processors, and for interrupt handling the users no longer need to be concerned about processor specific details like internal word lengths or logical memory names in the HOST system level program. The API introduces a minimum amount of code overhead with regard to linking the processor kernels to the HOST system level program.
V. IMPLEMENTATION RESULTS
The BRESCA processor is an array of 24 BRESCA cells. Each cell is a individual processor, running its own program. The BRESCA cell is a 9 issue slot VLIW processor. The array a handle tasks such as:
- DC Offset, IQ Gain, IQ Phase correction
- Frequency Correction
- Channel Filter
- Sample Rate Conversion
- Coarse & Fine Gain Control
- OFDM Time Base
The AVISPA processor is a VLIW processor with 42 issues slots. It can handle tasks such as:
- FFT
- Digital Time Sihft
- Common Phase Error
- Time Interpolation
- Frequency Interpolation
- Equalisation
- Differential Demodulation
The MOUSTIQUE iFEC processor is a VLIW processor with 15 slots. It handles tasks such as:
- Symbol deinterleaving
- Demapping
- Bit deinterleaving
- Bit multiplexing
- Depuncturing
The AVISPA FEC processor is a VLIW processor with 27 slots. It handles tasks such as:
- Viterbi error correction
- BER Computation
Finally, the MOUSTIQUE oFEC is a VLIW processor with 13 issue slots. It performs tasks like:
- Block Deinterleaving
- Reed-Solomon decoder
- Descrambling
- Framing functions
The initial versions of the OFDM signal processors are developed with significant margin in terms of program memory, data memory and available operations per second. This allows for large design space exploration for multiple standards and many new algorithms.
All five Silicon Hive processors combined are 800kgates and the cores have in total 290 kbit of program memory in the current configuration.
With the next generation of the OFDM processors we expect to significantly reduce the implementation cost. This reduction is achieved by removing the margin in memory size and available operations per second for each core. Also improving the efficiency of the software implementation and improving the algorithms will help in the reduction of the system.
Thanks to Silicon Hive’s capability to design and automatically generate processors along with their compatible C-based compilers, implementing the proposed design changes almost instantaneously leads to new RTL code and software development tools. Thus, the emphasis can be laid on specifying and analyzing optimization scenarios. The actual implementation of the concepts almost comes for free.
CONCLUSION
We presented a methodology for generating a set of flexible OFDM signal processors for digital baseband receiver designs. Starting from the decomposition of the OFDM system into its components, we explained the applied design and implementation flow for generating the initial set of
processors. Further optimization in terms of implementation performance is the next step. For this task, we will benefit from Silicon Hive’s ighly automated processor generation flow, which allows for a complete design iteration cycle in the order of hours.
References:
[1] Digital Video Broadcasting (DVB) for digital terrestrial television; ETSI standard EN 300 744 v.1.4.1 (2001-01)
[2] Transmission for digital terrestrial television broadcasting, ISDB-T; ARIB standard STD-B31 v.1.5
[3] Digital Audio Broadcasting; ETSI standard EN 300 401 v.1.3.2 (2000-09)
[4] Silicon Hive Technology Primer. www.SiliconHive.com
[5] Lex Augusteijn, The HiveCC Compiler for MassivelyParallel ULIW Cores, Embedded Processor Forum, San Jose, May 17-20, 2004
[6] J. Leijten, A Massively Parallel Reconfigurable ULIW Core, Microprocessor Forum, San. Jose, October 12, 2003.
Related Semiconductor IP
- Wi-Fi 7(be) RF Transceiver IP in TSMC 22nm
- PUF FPGA-Xilinx Premium with key wrap
- ASIL-B Ready PUF Hardware Premium with key wrap and certification support
- ASIL-B Ready PUF Hardware Base
- PUF Software Premium with key wrap and certification support
Related White Papers
- An Industrial Overview of Open Standards for Embedded Vision and Inferencing
- Emerging H.264 standard supports broadcast video encoding
- Developing and Integrating FPGA Co-processors with the TiC6X Family of DSP Processors
- Practical Case: Embedded Multiprocessor Design on a Flexible Hardware: NEO_CORE_CYCLONE_III
Latest White Papers
- Boosting RISC-V SoC performance for AI and ML applications
- e-GPU: An Open-Source and Configurable RISC-V Graphic Processing Unit for TinyAI Applications
- How to design secure SoCs, Part II: Key Management
- Seven Key Advantages of Implementing eFPGA with Soft IP vs. Hard IP
- Hardware vs. Software Implementation of Warp-Level Features in Vortex RISC-V GPU