Packet Architects offers a series of high speed switching IPs which are developed using the unique FlexSwitch toolchain. The toolchain allows a fast and flexible development of switching/routing IP for any packet based technology.
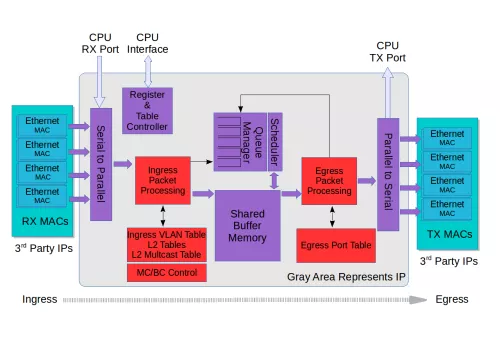
This L2 Ethernet Switching IP offers a full range of features with full wirespeed on all ports plus a high speed CPU port. Each port has priority queues which are controlled by a strict priority scheduler allowing the most timing critical packets to get minimal delay while providing a fairness between queues. The switching core is built around a shared buffer memory architecture allowing head of line blocking free switching on all ports operating at wirespeed. It offers dynamic per port and per priority usage of the packet buffer memory along with buffer limiters to limit how much an egress port / priority uses of total buffer memory. The switching core also features multiple VLAN tagging and untagging along with egress VLAN translation.
The L2 Ethernet Switching IP features a processor interface allowing setup of tables and register. It also features a packet based CPU port which can be used to both send and receive ethernet frames to/from the switching IP.
This IP requires no software setup to be used, it is ready to receive and forward Ethernet frames once downloaded to FPGA and connected to MACs. It has hardware learning for MAC addresses.
320Gbps Ethernet Switch
Overview
Key Features
- Switch throughput from 1 Gbit/s to 320 Gbit/s.
- Up to 8 x 40 Gigabit Ethernet ports or 24x10G or 48 x 1 Gigabit Ethernet ports.
- Dedicated port for packets to / from CPU (optional).
- Full wirespeed on all ports and all Ethernet frame sizes.
- Store and Forward shared memory architecture with 100kbit - 64 Mbit packet buffer.
- Support for any Jumbo frame size.
- Input and Output mirroring.
- 16K-128K L2 MAC table, hash based 4-way with optional hash collision CAM.
- 4K VLAN table with flexible push, swap, pop operations on VLAN tags plus egress vlan translation.
- 1K to 32K L2 multicast table.
- Automatic ageing and wire-speed learning of L2 addresses.
- Up to 4K Entry Learning FIFO for optional CPU based learning.
- Strict Priority Scheduler with 1-16 priority queues per egress port.
- Flexible mapping of 802.1q, MPLS Exp, IPv4/IPv6 TOS byte to egress queue priority.
- Spanning tree processing support.
- Resource counters with configurable limits per egress port, queue and multicast usage of buffer memory.
- Drop counters for packets dropped due to resource limits.
- Filtering based on destination and source MAC addresses.
- CPU interface for accessing registers and tables in IP.
- Queue management: disable queueing, disable scheduling, drain queue, redirect port.
- Multicast/Broadcast storm control based on packets/s or bandwidth per port.
- Integrates seamless with Xilinx and Altera 1GE and 10GE MACs.
Benefits
- Quick customization thanks to HLS-based packet processing, and a generated datapath
Block Diagram
Deliverables
- Verilog source code of IP.
- Datasheet of registers & theory of operations.
- C source code for accessing registers.
- Easy to parse YML file for register mapping.
- Verilog testbench.
Technical Specifications
Short description
320Gbps Ethernet Switch
Vendor
Vendor Name
Availability
Available Now