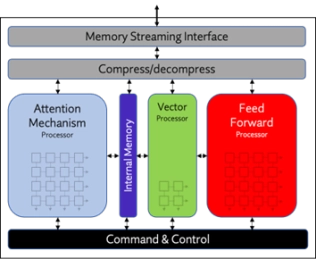
Neural Decision Processor IP
Filter
Compare
28
IP
from
11
vendors
(1
-
10)
-
All-analog Neural Signal Processor
- Analog AI Innovation: Blumind AMPL™ is a disruptive analog AI compute fabric for micropower artificial intelligence applications.
- Precision and Accuracy: Blumind all-analog AI compute delivers deterministic and precise inferencing performance at up to x1000 lower power than our competitors. Delivering higher efficiency and the longest battery life for always-on applications.
- Low Latency Solutions: AMPL™ fabric delivers efficient low latency for real-time applications.
- Analog Breakthrough: AMPL™ is the first all-analog AI on advanced standard CMOS architected to fundamentally mitigate process, voltage, temperature and drift variations.
-
Neuromorphic Processor IP (Second Generation)
- Supports 8-, 4-, and 1-bit weights and activations
- Programmable Activation Functions
- Skip Connections
- Support for Spatio-Temporal and Temporal Event-Based Neural Network
-
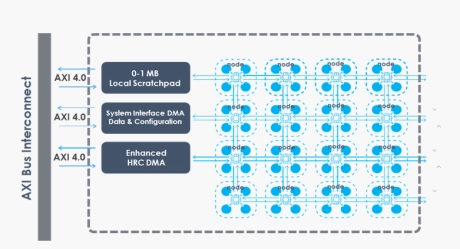
Run-time Reconfigurable Neural Network IP
- Customizable IP Implementation: Achieve desired performance (TOPS), size, and power for target implementation and process technology
- Optimized for Generative AI: Supports popular Generative AI models including LLMs and LVMs
- Efficient AI Compute: Achieves very high AI compute utilization, resulting in exceptional energy efficiency
- Real-Time Data Streaming: Optimized for low-latency operations with batch=1

-
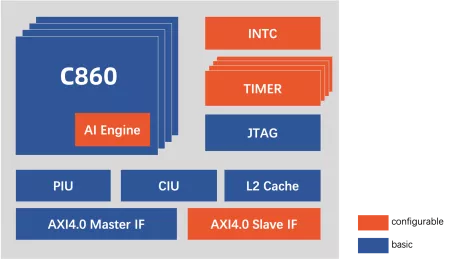
High-performance 32-bit multi-core processor with AI acceleration engine
- Instruction set: T-Head ISA (32-bit/16-bit variable-length instruction set);
- Multi-core: Isomorphic multi-core, with 1 to 4 optional cores;
- Pipeline: 12-stage;
- Microarchitecture: Tri-issue, deep out-of-order;
-
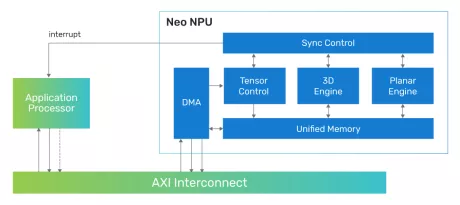
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
NPU IP for Wearable and IoT Market
- ML inference engine for deeply embedded system
NN Engine
Supports popular ML frameworks
Support wide range of NN algorithms and flexible in layer ordering
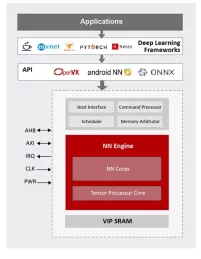
- ML inference engine for deeply embedded system
-
NPU IP Core for Data Center
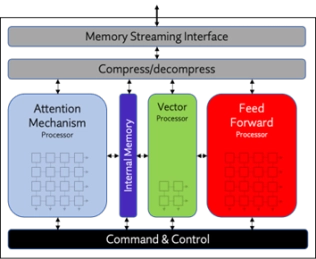
- Origin Evolution™ for Data Center offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks. Featuring a hardware and software co-designed architecture, Origin Evolution for Data Center scales to 128 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
High-Performance NPU
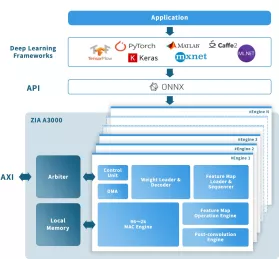
- The ZIA™ A3000 AI processor IP is a low-power processor specifically designed for edge-side neural network inference processing.
- This versatile AI processor offers general-purpose DNN acceleration, empowering customers with the flexibility and configurability to optimize performance for their specific PPA targets.
- A3000 also supports high-precision inference, reducing CPU workload and memory bandwidth.
-
AI SDK for Ceva-NeuPro NPUs
- Ceva-NeuPro Studio is a comprehensive software development environment designed to streamline the development and deployment of AI models on the Ceva-NeuPro NPUs.
- It offers a suite of tools optimized for the Ceva NPU architectures, providing network optimization, graph compilation, simulation, and emulation, ensuring that developers can train, import, optimize, and deploy AI models with highest efficiency and precision.
-
NPU IP Core for Edge
- Origin Evolution™ for Edge offers out-of-the-box compatibility with today's most popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of networks and representations.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Edge scales to 32 TFLOPS in a single core to address the most advanced edge inference needs.