Deep Learning Processor IP
Filter
Compare
25
IP
from
12
vendors
(1
-
10)
-
Deep Learning Processor
- High performance: Whether it’s at the edge or in the cloud, videantis' processors provide the required performance.
- Scalable architecture: 1 to 1000+ cores address ultra-low cost to high-performance applications.
- Ultra-high MAC throughput: Each core computes a high number of MACs per cycle, resulting in an abundant amount of processing performance in multi-core systems.
-
High Performance 64-bit RISC-V Processor
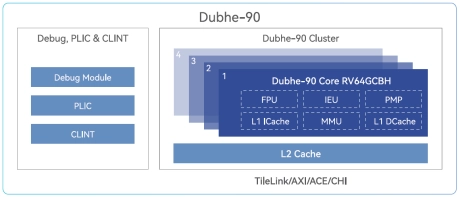
- Dubhe-90 is a high-performance commercial RISC-V CPU Core IP that is deliverable.
- It adopts an 11+ stage and 5-issue pipeline, superscalar, and deep out-of-order execution, and supports standard RISC-V RV64GCBH extensions.
-
High Performance RISC-V Processor for Edge Computing
- Superscalar / Out-of-order Execution / 3-issue / 8-stage Pipeline
- High level of configurablity and design scalability
-
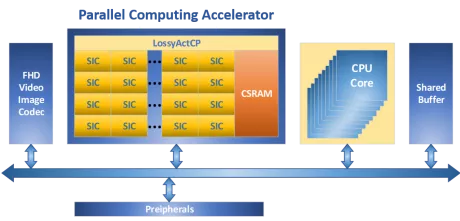
Low-power high-speed reconfigurable processor to accelerate AI everywhere.
- Multi-Core Number: 4
- Performance (INT8, 600MHz): 0.6TOPS
- Achievable Clock Speed (MHz): 600 (28nm)
- Synthesis Logic Gates (MGates): 2
-
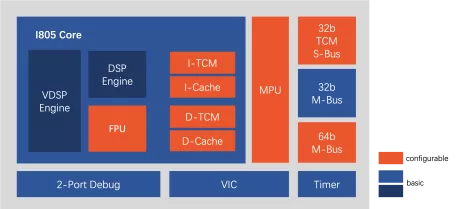
AIoT processor with vector computing engine
- Instruction set: T-Head ISA (32-bit/16-bit variable-length instruction set);
- Pipeline: 4-stage sequential pipeline;
- General register: 32 32-bit GPRs; 16 128-bit VGPRs;
- Cache: I-Cache: 8 KB/16 KB/32 KB/64 KB (size options); D-Cache: 8 KB/16 KB/32 KB/64 KB (size options);
-
Neural network processor designed for edge devices
- High energy efficiency
- Support mainstream deep learning frameworks
- Low power consumption
- An integrated AI solution
-
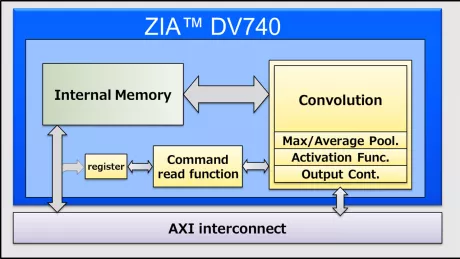
AI inference processor IP
- High Performance, Low Power Consumption, Small Foot Print IP for Deep Learning inference processing.
-
ARC EV Processors are fully programmable and configurable IP cores that are optimized for embedded vision applications
- ARC processor cores are optimized to deliver the best performance/power/area (PPA) efficiency in the industry for embedded SoCs. Designed from the start for power-sensitive embedded applications, ARC processors implement a Harvard architecture for higher performance through simultaneous instruction and data memory access, and a high-speed scalar pipeline for maximum power efficiency. The 32-bit RISC engine offers a mixed 16-bit/32-bit instruction set for greater code density in embedded systems.
- ARC's high degree of configurability and instruction set architecture (ISA) extensibility contribute to its best-in-class PPA efficiency. Designers have the ability to add or omit hardware features to optimize the core's PPA for their target application - no wasted gates. ARC users also have the ability to add their own custom instructions and hardware accelerators to the core, as well as tightly couple memory and peripherals, enabling dramatic improvements in performance and power-efficiency at both the processor and system levels.
- Complete and proven commercial and open source tool chains, optimized for ARC processors, give SoC designers the development environment they need to efficiently develop ARC-based systems that meet all of their PPA targets.
-
DPU for Convolutional Neural Network
- Configurable hardware architecture
- Configurable core number up to three
- Convolution and deconvolution
-
TPU IoT/Edge Licensable Hardware IP
- The Prodigy is the first Universal Processor combining General Purpose Processors, High Performance Computng (HPC), Artficial Intelligence (AI), Deep Machine Learning, Explainable AI, Bio AI, and other AI disciplines with a single chip.
- With the tremendous growth of the AI chipset market for edge inference, Tachyum TPU (Tachyum Processing Unit) is positoned to expand the unique value propositon of its Tachyum Prodigy based training to its TPU AI Inference Engine, as a licensable core.