AI processor IP
Filter
Compare
307
IP
from
46
vendors
(1
-
10)
-
Dataflow AI Processor IP
- Revolutionary dataflow architecture optimized for AI workloads with spatial compute arrays, intelligent memory hierarchies, and runtime reconfigurable elements
-
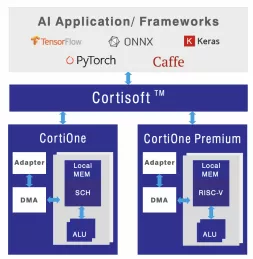
AI Processor Accelerator
- Universal Compatibility: Supports any framework, neural network, and backbone.
- Large Input Frame Handling: Accommodates large input frames without downsizing.
-
Powerful AI processor
- SiFive Intelligence Extensions for ML workloads
- 512-bit VLEN
- Performance benchmarks
- Built on silicon-proven U7-Series core
-
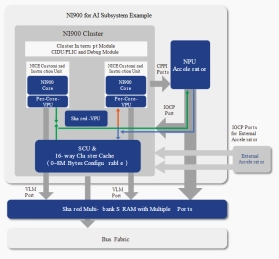
AI DSA Processor - 9-Stage Pipeline, Dual-issue
- NI900 is a DSA processor based on 900 Series.
- NI900 is optimized with features specifically targeting AI applications.
-
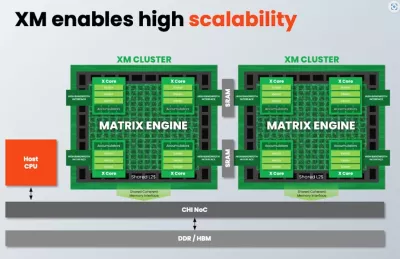
High-performance AI dataflow processor with scalable vector compute capabilities
- Matrix Engine
- 4 X-Cores per cluster
- 1 Cluster = 16 TOPS (INT8)
-
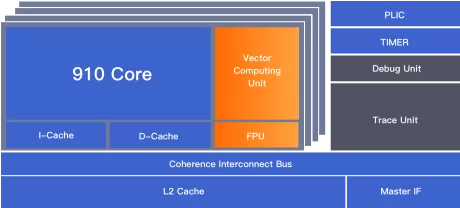
High-performance 64-bit RISC-V architecture multi-core processor with AI vector acceleration engine
- Instruction set: RISC-V RV64GC/RV 64GCV;
- Multi-core: Isomorphic multi-core with 1 to 4 optional clusters. Each cluster can have 1 to 4 optional cores;
-
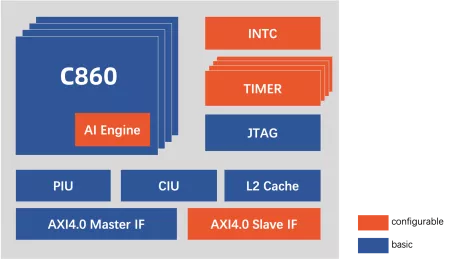
High-performance 32-bit multi-core processor with AI acceleration engine
- Instruction set: T-Head ISA (32-bit/16-bit variable-length instruction set);
- Multi-core: Isomorphic multi-core, with 1 to 4 optional cores;
- Pipeline: 12-stage;
- Microarchitecture: Tri-issue, deep out-of-order;
-
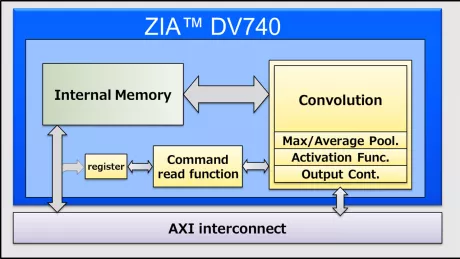
AI inference processor IP
- High Performance, Low Power Consumption, Small Foot Print IP for Deep Learning inference processing.
-
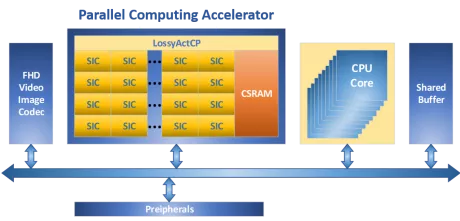
Low-power high-speed reconfigurable processor to accelerate AI everywhere.
- Multi-Core Number: 4
- Performance (INT8, 600MHz): 0.6TOPS
- Achievable Clock Speed (MHz): 600 (28nm)
- Synthesis Logic Gates (MGates): 2
-
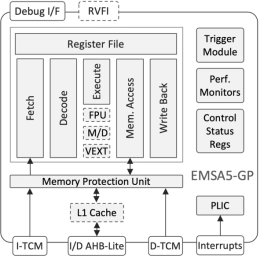
Vector-Capable Embedded RISC-V Processor
- The EMSA5-GP is a highly-featured 32-bit RISC-V embedded processor IP core optimized for processing-demanding applications.
- It is equipped with floating-point and vector-processing units, cache memories, and is suitable for concurrent execution in a multi-processor environment.