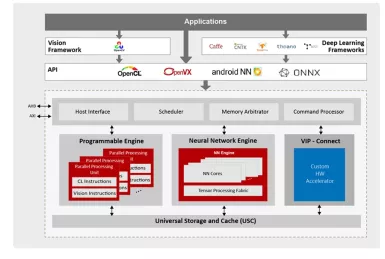
AI Inference Accelerator IP
Filter
Compare
16
IP
from
11
vendors
(1
-
10)
-
AI Accelerator Specifically for CNN
- A specialized hardware with controlled throughput and hardware cost/resources, utilizing parameterizeable layers, configurable weights, and precision settings to support fixed-point operations.
- This hardware aim to accelerate inference operations, particulary for CNNs such as LeNet-5, VGG-16, VGG-19, AlexNet, ResNet-50, etc.
-
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
-
Neural engine IP - Balanced Performance for AI Inference
- The Origin™ E2 is a family of power and area optimized NPU IP cores designed for devices like smartphones and edge nodes.
- It supports video—with resolutions up to 4K and beyond— audio, and text-based neural networks, including public, custom, and proprietary networks.
-
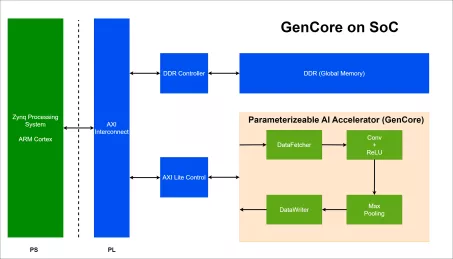
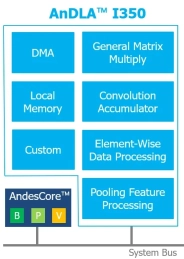
High performance-efficient deep learning accelerator for edge and end-point inference
- Configurable MACs from 32 to 4096 (INT8)
- Maximum performance 8 TOPS at 1GHz
- Configurable local memory: 16KB to 4MB
-
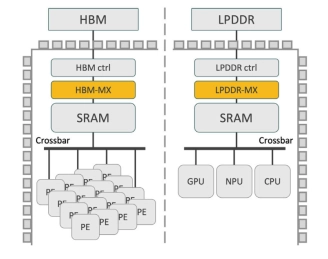
High-Performance Memory Expansion IP for AI Accelerators
- Expand Effective HBM Capacity by up to 50%
- Enhance AI Accelerator Throughput
- Boost Effective HBM Bandwidth
- Integrated Address Translation and memory management:
-
RISC-V AI Acceleration Platform - Scalable, standards-aligned soft chiplet IP
- Built on RISC-V and delivered as soft chiplet IP, the Veyron E2X provides scalable, standards-based AI acceleration that customers can integrate and customize freely.

-
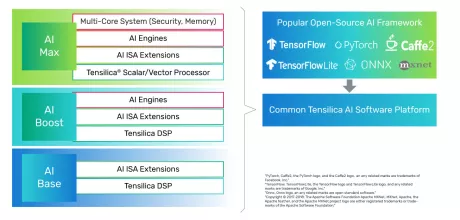
Tensilica AI Max - NNA 110 Single Core
- Scalable Design to Adapt to Various AI Workloads
- Efficient in Mapping State-of-the-Art DL/AI Workloads
- End-to-End Software Toolchain for All Markets and Large Number of Frameworks
-
Neural engine IP - The Cutting Edge in On-Device AI
- The Origin E6 is a versatile NPU that is customized to match the needs of next-generation smartphones, automobiles, AV/VR, and consumer devices.
- With support for video, audio, and text-based AI networks, including standard, custom, and proprietary networks, the E6 is the ideal hardware/software co-designed platform for chip architects and AI developers.
- It offers broad native support for current and emerging AI models, and achieves ultra-efficient workload scheduling and memory management, with up to 90% processor utilization—avoiding dark silicon waste.
-
AI SDK for Ceva-NeuPro NPUs
- Ceva-NeuPro Studio is a comprehensive software development environment designed to streamline the development and deployment of AI models on the Ceva-NeuPro NPUs.
- It offers a suite of tools optimized for the Ceva NPU architectures, providing network optimization, graph compilation, simulation, and emulation, ensuring that developers can train, import, optimize, and deploy AI models with highest efficiency and precision.
-
NPU IP for AI Vision and AI Voice
- 128-bit vector processing unit (shader + ext)
- OpenCL 3.0 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b