e-GPU: An Open-Source and Configurable RISC-V Graphic Processing Unit for TinyAI Applications
By Simone Machetti, Pasquale Davide Schiavone, Lara Orlandic, Darong Huang, Deniz Kasap, Giovanni Ansaloni, David Atienza
Embedded Systems Laboratory (ESL), EPFL, Lausanne, Switzerland
Abstract
Graphics processing units (GPUs) excel at parallel processing, but remain largely unexplored in ultra-low-power edge devices (TinyAI) due to their power and area limitations, as well as the lack of suitable programming frameworks. To address these challenges, this work introduces embedded GPU (e-GPU), an open-source and configurable RISC-V GPU platform designed for TinyAI devices. Its extensive configurability enables area and power optimization, while a dedicated Tiny-OpenCL implementation provides a lightweight programming framework tailored to resource-constrained environments. To demonstrate its adaptability in real-world scenarios, we integrate the e-GPU with the eXtendible Heterogeneous Energy-Efficient Platform (XHEEP) to realize an accelerated processing unit (APU) for TinyAI applications. Multiple instances of the proposed system, featuring varying e-GPU configurations, are implemented in TSMC’s 16nm SVT CMOS technology and are operated at 300MHz and 0.8 V. Their area and leakage characteristics are analyzed to ensure alignment with TinyAI constraints. To assess both runtime overheads and application-level efficiency, we employ two benchmarks: General Matrix Multiply (GeMM) and biosignal processing (TinyBio) workloads. The GeMM benchmark is used to quantify the scheduling overhead introduced by the Tiny- OpenCL framework. The results show that the delay becomes negligible for matrix sizes larger than 256 × 256 (or equivalent problem sizes). The TinyBio benchmark is then used to evaluate performance and energy improvements in the baseline host. The results demonstrate that the high-range e-GPU configuration with 16 threads achieves up to a 15.1 × speed-up and reduces energy consumption by up to 3.1 × , while incurring only a 2.5 × area overhead and operating within a 28mW power budget.
Index Terms—Ultra-Low-Power, Open-Source, Graphic Processing Unit, Microcontroller, Artificial Intelligence.
I. INTRODUCTION
The growing need for machine learning-based real-time computing has fueled the rapid expansion of edge computing. By processing data locally rather than relying on cloud servers, edge computing reduces latency, enhances privacy, and improves energy efficiency, making it an ideal solution for numerous edge applications. However, these workloads impose limitations on computational performance, real-time responsiveness, and power consumption, necessitating specialized hardware architectures.
A promising approach to meeting these challenges is the adoption of heterogeneous architectures, which integrate a host central processing unit (CPU) with domain-specific accelerators to balance efficiency and performance. Among these accelerators, graphics processing units (GPUs) have proven particularly effective in exploiting data parallelism for machine learning and signal processing tasks. When coupled with host CPUs, GPUs form accelerated processing units (APUs), enabling a unified platform that efficiently handles both general-purpose tasks and computationally intensive workloads.
While various GPU implementations exist, ranging from high-performance to embedded solutions, their trade-offs in the context of ultra-low-power edge devices (TinyAI) remain largely unexplored. These battery-powered devices operate under tight power constraints, typically in the range of tens of milliwatts, necessitating highly efficient GPU architectures. Their small form factor also imposes strict area restrictions, with a complete system-on-chip (SoC) occupying only a few square millimeters. Moreover, the absence of a file system and multi-threading support prevents the use of traditional GPU programming frameworks, such as standard open computing language (OpenCL) implementations, necessitating custom optimizations. Due to the aforementioned limitations, ultra-low-power devices typically rely on specialized accelerators such as coarsegrained reconfigurable arrays (CGRAs), systolic arrays, and near-memory or in-memory computing solutions, while the potential of GPUs in this domain remains largely unexplored.
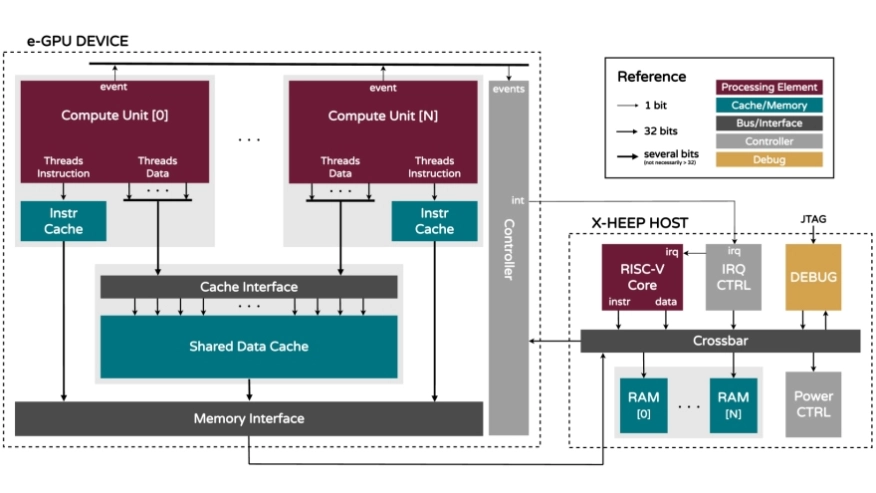
This work examines the feasibility and trade-offs associated with utilizing GPUs for TinyAI applications by introducing an open-source and configurable RISC-V platform, embedded GPU (e-GPU). The extensive configurability of the platform enables area and power optimization to meet the requirements of this domain. Furthermore, a custom tiny open computing language (Tiny-OpenCL) implementation overcomes the aforementioned limitations and provides a lightweight programming framework specifically developed for resourceconstrained devices. To demonstrate the adaptability of the proposed platform in real-world scenarios, we integrate the e-GPU with the eXtendible Heterogeneous Energy-Efficient Platform (X-HEEP) to realize an APU for TinyAI workloads.
Multiple instances of the proposed system, featuring varying e-GPU configurations, are implemented in TSMC’s 16 nm SVT CMOS technology and are operated at 300MHz and 0.8 V. Their area and leakage characteristics are analyzed to ensure alignment with TinyAI constraints. To assess both runtime overheads and application-level efficiency, we employ two benchmarks: General Matrix Multiply (GeMM) and bio-signal processing (TinyBio) workloads. The GeMM benchmark is used to quantify the scheduling overhead introduced by the Tiny-OpenCL framework, while the TinyBio benchmark is then used to evaluate performance and energy improvements over the baseline host.
The key contributions of this work are as follows:
- We advocate domain-specific GPUs as a suitable solution for the TinyAI domain.
- We present e-GPU [12], an open-source and configurable RISC-V GPU platform designed for TinyAI workloads.
- We analyze the programming limitations of this application domain and introduce a Tiny-OpenCL framework for resource-constrained devices.
- We explore the feasibility and trade-offs of utilizing GPUs for TinyAI applications.
- We release an open-source repository, including the complete e-GPU1 to allow researchers to tailor the platform to their TinyAI domains.
The remainder of this paper is organized as follows. Section 2 discusses related works. Section 3 summarizes background concepts. Section 4 describes the e-GPU hardware, while Section 5 focuses on the e-GPU software. Section 6 explains the integration with a host. Section 7 outlines the experimental setup, and Section 8 presents the experimental results. Finally, Section 9 concludes the paper.
To read the full article, click here
Related Semiconductor IP
- E-Series GPU IP
- Arm's most performance and efficient GPU till date, offering unparalled mobile gaming and ML performance
- Highest performance automotive GPU IP, with revolutionary functional safety technology
- High performance GPU for cloud gaming with DirectX support
- Arm’s latest flagship GPU is based on the new 5th Gen GPU architecture, bringing the next generation of visual computing to mobile
Related Articles
- An Open-Source Approach to Developing a RISC-V Chip with XiangShan and Mulan PSL v2
- Boosting RISC-V SoC performance for AI and ML applications
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Why RISC-V is a viable option for safety-critical applications
Latest Articles
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks