NPU IP
Filter
Compare
74
IP
from
22
vendors
(1
-
10)
-
RISC-V-Based, Open Source AI Accelerator for the Edge
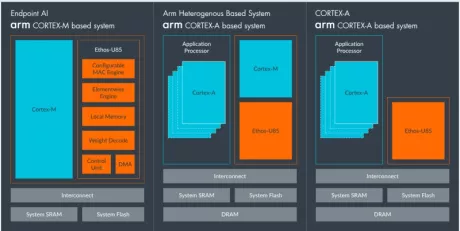
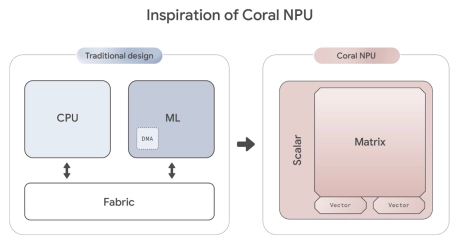
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
-
NPU IP Core for Edge
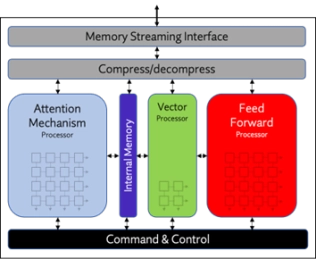
- Origin Evolution™ for Edge offers out-of-the-box compatibility with today's most popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of networks and representations.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Edge scales to 32 TFLOPS in a single core to address the most advanced edge inference needs.
-
NPU IP Core for Mobile
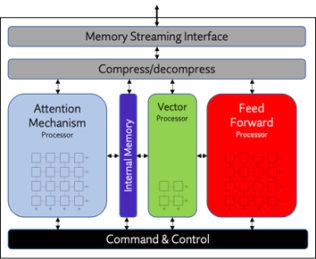
- Origin Evolution™ for Mobile offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Mobile scales to 64 TFLOPS in a single core.
-
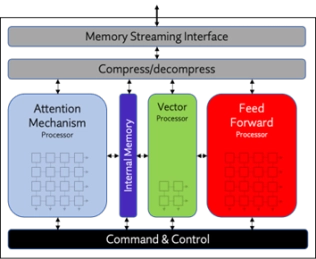
NPU IP Core for Data Center
- Origin Evolution™ for Data Center offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks. Featuring a hardware and software co-designed architecture, Origin Evolution for Data Center scales to 128 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
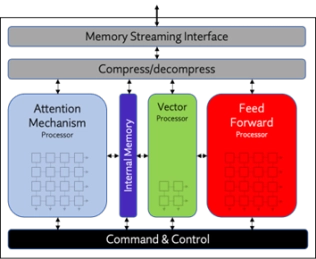
NPU IP Core for Automotive
- Origin Evolution™ for Automotive offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Automotive scales to 96 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
All-In-One RISC-V NPU
- Optimized Neural Processing for Next-Generation Machine Learning with High-Efficiency and Scalable AI compute

-
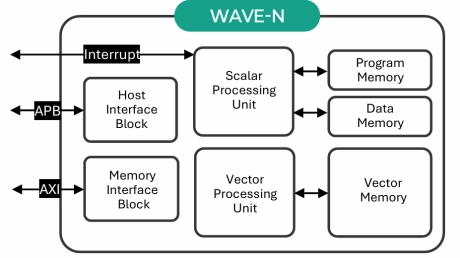
Specialized Video Processing NPU IP for SR, NR, Demosaic, AI ISP, Object Detection, Semantic Segmentation
- WAVE-N is a high-performance, video-specialized NPU IP designed to deliver real-time, deep learning-based image enhancement for edge devices.
- By utilizing a proprietary 'Line-by-Line' processing architecture, it significantly reduces DRAM bandwidth and achieves 4x to 10x faster processing speeds compared to conventional NPUs.
-
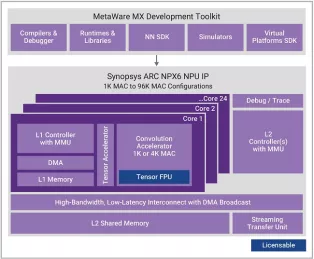
Optional extension of NPX6 NPU tensor operations to include floating-point support with BF16 or BF16+FP16
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
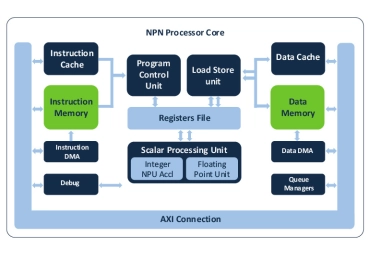
NPU IP for Embedded ML
- Fully programmable to efficiently execute Neural Networks, feature extraction, signal processing, audio and control code
- Scalable performance by design to meet wide range of use cases with MAC configurations with up to 64 int8 (native 128 of 4x8) MACs per cycle
- Future proof architecture that supports the most advanced ML data types and operators
-