Packet Architects offers a series of high speed switching/routing IP cores developed using the unique FlexSwitch tool-chain. This allows us to provide an optimized custom IP core within days of receiving customer requirements.
Packet Architects can provide IP cores with a full range of Ethernet switching and routing features such as IPv4/IPv6 routing, L2 switching, MPLS switching, advanced VLAN handling, classification, automatic learning etc.
The core is built around a shared buffer memory architecture providing wire-speed switching and routing on all ports without head of line blocking. It offers dynamic allocation of packet buffers per port and priority to avoid starvation due to over-allocation. Advanced QoS features allow the most timing critical packets to get minimal delay while providing fairness between traffic classes.
No initial software setup is required and due to the hardware learning for MAC addresses the core is ready to receive and forward Ethernet frames immediately once powered up. There is a high performance processor interface for register configuration, and a high performance dedicated CPU port for slow path processing of packets.
The design is optimized for both FPGA and ASIC technology but does not have any dependencies on the underlying technology. If the target technology has TCAMs these can be utilized.
Ethernet Switch / Router IP Core - Efficient and Massively Customizable
Overview
Key Features
- Full wire-speed on all ports for all Ethernet frame sizes.
- Store and Forward shared memory architecture.
- Support for Jumbo frame packets of any size limited only by the available packet buffer memory.
- Input and Output mirroring.
- IPv4/IPv6 routing with longest prefix match and direct host tables.
- MPLS switching supporting push/pop/swap/penultimate-pop operations.
- Virtual Routing Functions allowing per customer routing tables.
- ECMP next hop selection.
- Classification on L2 source and destination address, VLAN and Ethernet Type.
- Classification on L3 source and destination address, TOS and protocol.
- Classification on L4 source and destination ports.
- Classification actions are drop packet, send to CPU, redirect to port, assign a new egress queue priority and update statistics, update VLAN header.
- Ingress and Egress packet filtering based on protocol type, VLAN, L3 protocol, L4 protocol.
- Source MAC and Destination MAC range filtering with actions to drop, send to CPU, send to port and assign queue priority
- Hash based L2 MAC table with optional hash collision CAM and support for static entries. Support for unicast and multicast L2 forwarding.
- Hardware based wire-speed learning and aging of L2 addresses. Optional hardware assisted software learning and aging.
- VLAN table optionally supporting more than 4k entries.
- Packet VLAN operations are push, pop, swap, penultimate-pop. Up to three operations per packet can be performed.
- Flexible mapping of 802.1q, MPLS Exp, IPv4/IPv6 TOS byte to egress queue priority.
- Scheduling based on a combination of strict priority schedulers, deficit weighted round robin (DWRR) queue schedulers and rate limiting token buckets. 1-8 queues per egress port.
- Link aggregation with configurable field selection for the hash function.
- Spanning tree & Multiple spanning tree support.
- Buffer memory resource management with configurable limits per egress port and queue ensuring separation for all traffic classes.
- Drop counters for all packet drop cases.
- CPU interface supporting multiple outstanding transactions for high speed access.
- Dedicated port for packets to / from CPU with additional packet header to simplify software processing and controlling processing of packets from CPU. Support for setting queue priority and packet truncation based on packet type.
- Queue management: disable queuing, disable scheduling, drain queue, redirect port.
- Multicast/Broadcast storm control based on packet rate or byte rate per port with separate rates for flooding, broadcast and multicast.
- Integrates seamless with Open Cores, Xilinx and Intel MACs.
- IEEE 1588v2 PTP Transparent Clock two-step support.
Benefits
- Quick customization thanks to a massively parametrized design, and the unique FlexSwitch tool-chain
- Port speeds from 10 Mbit/s to 100 Gbit/s. Mixed port speeds are supported.
- Number of ports from 4 to 128 with optimized design for each configuration.
- All table sizes can be configured such as L2 hash tables, VLAN tables, L3 LPM and direct host tables, classification tables etc.
- Most features can selectively be added or removed and the design will be automatically optimized for the chosen feature set.
- Design, datasheet and YAML files are automatically created based on the chosen parameter set.
- Delivered as non-encrypted, human readable, verilog source code
Block Diagram
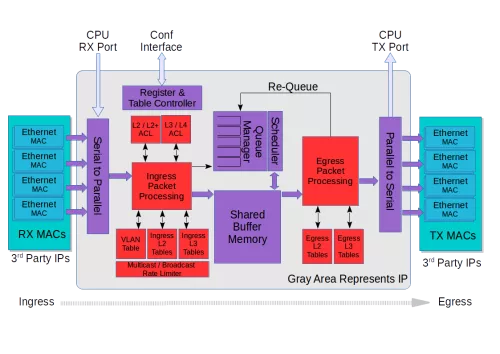
Applications
- Enterprise swiches
- Carrier switches
- Datacenter switches
- ToR swiches
- 5G networks
Deliverables
- IP core delivered as non-encrypted Verilog 2001 source code.
- Datasheet with theory of operations and automatically created register description.
- Easy to parse YAML file for register mapping.
- Verilog testbench for checking simulator compliance and as an example of driving the cores interfaces.
- Low-level device driver
Technical Specifications
Short description
Ethernet Switch / Router IP Core - Efficient and Massively Customizable
Vendor
Vendor Name
Foundry, Node
The RTL is not foundry dependent
Availability
Available Now
Related IPs
- 1G/10G/25G/50G/100G Ethernet Switch IP Core - Efficient and Massively Customizable
- Ethernet TSN Switch IP Core - Efficient and Massively Customizable
- Efficient microcontroller core with a 5-stage in-order pipeline, privilege modes, an MPU, L1 and L2 caches
- Efficient microcontroller core with a 5-stage in-order pipeline, privilege modes, an FPU, an MPU, L1 and L2 caches
- Efficient Linux-capable application core with a 9-stage in-order pipeline, an MMU, L1 and L2 caches, and cache coherency
- OpenGL ES 2.0 3D graphics IP core for FPGAs and ASICs