Neural Accelerator AI Processor IP
Filter
Compare
22
IP
from
8
vendors
(1
-
10)
-
AI Processor Accelerator
- Universal Compatibility: Supports any framework, neural network, and backbone.
- Large Input Frame Handling: Accommodates large input frames without downsizing.
-
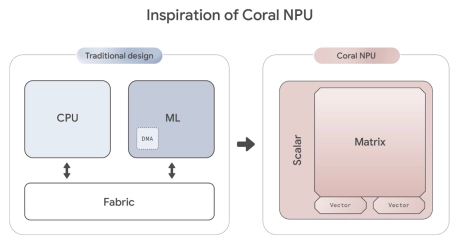
RISC-V-Based, Open Source AI Accelerator for the Edge
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
-
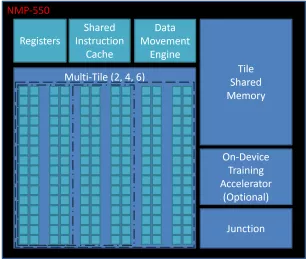
Performance AI Accelerator for Edge Computing
- Up to 16 TOPS
- Up to 16 MB Local Memory
- RISC-V/Arm Cortex-R or A 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
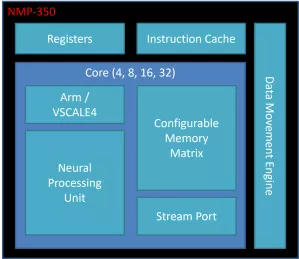
Performance Efficiency AI Accelerator
- Up to 6 TOPS
- Up to 6 MB Local Memory
- RISC-V/Arm Cortex-M or A 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
Lowest Power and Cost End Point AI Accelerator
- Up to 1 TOPS
- Up to 1 MB Local Memory
- RISC-V/Arm Cortex-M 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
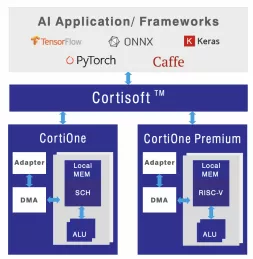
Run-time Reconfigurable Neural Network IP
- Customizable IP Implementation: Achieve desired performance (TOPS), size, and power for target implementation and process technology
- Optimized for Generative AI: Supports popular Generative AI models including LLMs and LVMs
- Efficient AI Compute: Achieves very high AI compute utilization, resulting in exceptional energy efficiency
- Real-Time Data Streaming: Optimized for low-latency operations with batch=1

-
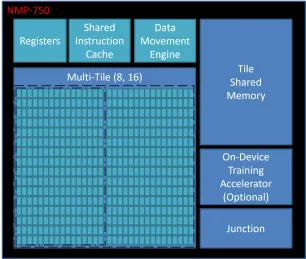
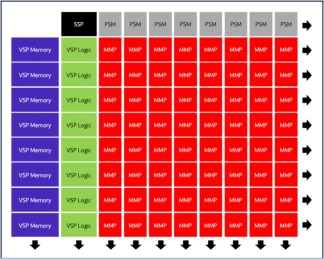
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
-
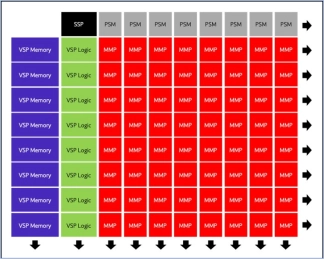
Neural engine IP - The Cutting Edge in On-Device AI
- The Origin E6 is a versatile NPU that is customized to match the needs of next-generation smartphones, automobiles, AV/VR, and consumer devices.
- With support for video, audio, and text-based AI networks, including standard, custom, and proprietary networks, the E6 is the ideal hardware/software co-designed platform for chip architects and AI developers.
- It offers broad native support for current and emerging AI models, and achieves ultra-efficient workload scheduling and memory management, with up to 90% processor utilization—avoiding dark silicon waste.
-
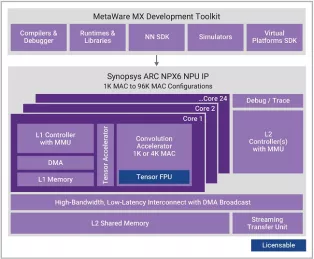
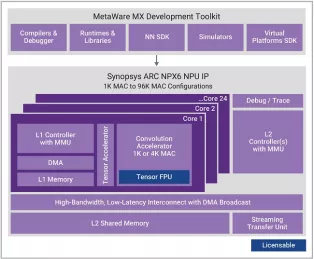
Enhanced Neural Processing Unit providing 4096 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
Enhanced Neural Processing Unit providing 1024 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator