Energy Processing Unit IP
Filter
Compare
27
IP
from
11
vendors
(1
-
10)
-
ARC NPX Neural Processing Unit (NPU) IP supports the latest, most complex neural network models and addresses demands for real-time compute with ultra-low power consumption for AI applications
- ARC processor cores are optimized to deliver the best performance/power/area (PPA) efficiency in the industry for embedded SoCs. Designed from the start for power-sensitive embedded applications, ARC processors implement a Harvard architecture for higher performance through simultaneous instruction and data memory access, and a high-speed scalar pipeline for maximum power efficiency. The 32-bit RISC engine offers a mixed 16-bit/32-bit instruction set for greater code density in embedded systems.
- ARC's high degree of configurability and instruction set architecture (ISA) extensibility contribute to its best-in-class PPA efficiency. Designers have the ability to add or omit hardware features to optimize the core's PPA for their target application - no wasted gates. ARC users also have the ability to add their own custom instructions and hardware accelerators to the core, as well as tightly couple memory and peripherals, enabling dramatic improvements in performance and power-efficiency at both the processor and system levels.
- Complete and proven commercial and open source tool chains, optimized for ARC processors, give SoC designers the development environment they need to efficiently develop ARC-based systems that meet all of their PPA targets.
-
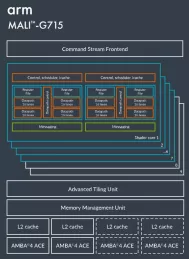
Fourth-generation Valhall-based graphics processing unit (GPU) for premium mobile market
- Variable Rate Shading for Performance and Energy Boost
- Evolving Execution Engine for Greater Compute Power
- Massive ML Uplift for Advanced Intelligence
-
Second-Generation Valhall-based Graphics Processing Unit (GPU) for the Mainstream Market
- Top Performance for 8K High Res
- Highly Scalable GPU
- Improving Device Battery Life
-
Third-Generation Valhall-based Graphics Processing Unit (GPU) for the sub-premium market
- Redesigned Execution Engine for Lower-Cost Gaming
- Improved Quality for Smartphone Market Growth
- Industry-Leading Battery Efficiency
-
Third-Generation Valhall-based Graphics Processing Unit (GPU) for Premium Market
- Command Stream Frontend for Advanced Gaming
- Large Cores Provide Highest-Ever Energy Efficiency
- ML Uplift Brings More Advanced Experiences to Mobile
-
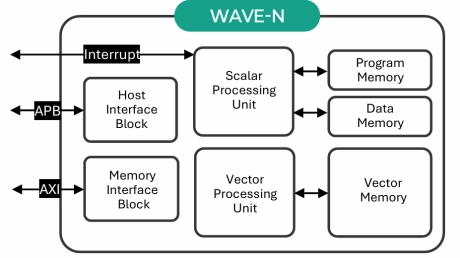
Specialized Video Processing NPU IP for SR, NR, Demosaic, AI ISP, Object Detection, Semantic Segmentation
- WAVE-N is a high-performance, video-specialized NPU IP designed to deliver real-time, deep learning-based image enhancement for edge devices.
- By utilizing a proprietary 'Line-by-Line' processing architecture, it significantly reduces DRAM bandwidth and achieves 4x to 10x faster processing speeds compared to conventional NPUs.
-
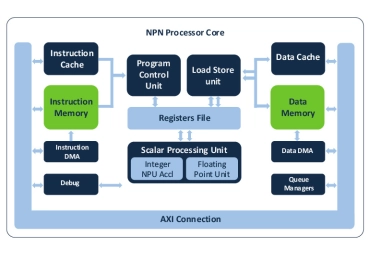
NPU IP for Embedded ML
- Fully programmable to efficiently execute Neural Networks, feature extraction, signal processing, audio and control code
- Scalable performance by design to meet wide range of use cases with MAC configurations with up to 64 int8 (native 128 of 4x8) MACs per cycle
- Future proof architecture that supports the most advanced ML data types and operators
-
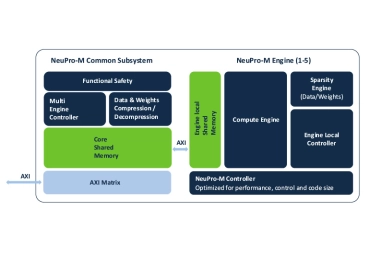
Scalable Edge NPU IP for Generative AI
- Ceva-NeuPro-M is a scalable NPU architecture, ideal for transformers, Vision Transformers (ViT), and generative AI applications, with an exceptional power efficiency of up to 3500 Tokens-per-Second/Watt for a Llama 2 and 3.2 models
- The Ceva-NeuPro-M Neural Processing Unit (NPU) IP family delivers exceptional energy efficiency tailored for edge computing while offering scalable performance to handle AI models with over a billion parameters.
-
IP cores for ultra-low power AI-enabled devices
- Ultra-fast Response Time
- Zero-latency Switching
- Low Power