Automotive MCU IP
Filter
Compare
17
IP
from
9
vendors
(1
-
10)
-
8-bit MCU
- FAST architecture, 4 times faster than the original implementation
- Software compatible with industry standard 68HC11
- 10 times faster multiplication
- 16 times faster division
-
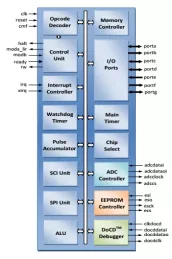
8-bit Microcontroller IP - legacy architecture - raplacement of 68HC11K MCU's
- Cycle compatible with original implementation
- Software compatible with 68HC11K industry standard
- I/O Wrapper, making it pin-compatible core
- SFR registers remapped to any 4KB memory page
-
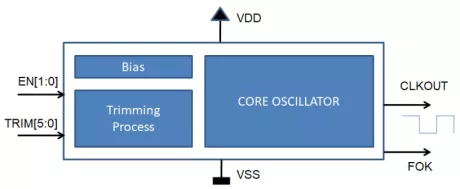
Ultra-low power 32 kHz RC oscillator - High temperature (Grade 1, Tj=150°)
- Ultra-low power for best-in-class power consumption of the always-on domain during sleep / deep sleep modes
- Fast wake-up
- Active, shutdown and stand-by modes
-
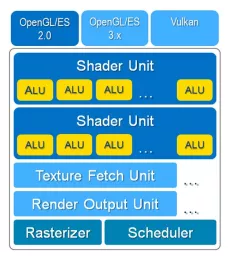
OpenGL ES 2.0 3D graphics IP core for FPGAs and ASICs
- D/AVE NX is the latest and most powerful addition to the D/AVE family of rendering cores.
- It is the first IP to bring 3D graphics OpenGL ES 2.0 rendering (with some ES 3.0 / 3.1 extensions) to the FPGA and SoC world and – with offline-shader compilers – even into MCUs or low-end MPUs with small amounts of memory and bare-metal or RTOS operation systems.
-
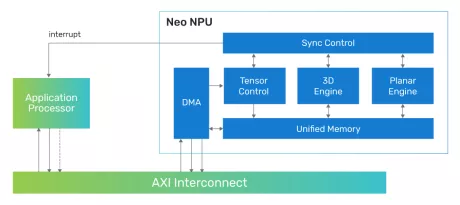
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
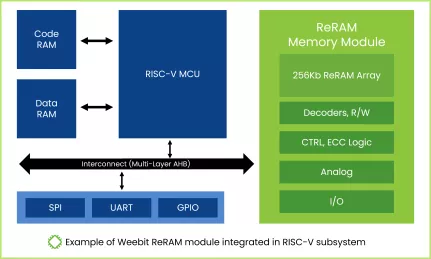
ReRAM NVM in SkyWater 130nm
- Weebit Resistive RAM (ReRAM) is a new type of Non-Volatile Memory (NVM) that is designed to be the successor to flash memory.
- Weebit ReRAM IP can provide a high level of differentiation for System-on-Chip (SoC) designs, with performance, power, cost, security, environmental, and a range of additional advantages compared to flash and other NVMs.
- Weebit’s first ReRAM IP product is available now in SkyWater Technology’s 130nm CMOS process (S130). The technology is fully qualified, available for integration in SkyWater’s users’ SoCs, and ready for production.
-
Telematics Processors IP
- Core and infrastructure
- ? ARM® Cortex™-R4 MCU
- ? Embedded SRAM
- ? SDRAM controller
-
8-bit FAST Microcontroller
- FAST architecture, 4 times faster than the original implementation
- Software compatible with industry standard 68HC11
- 10 times faster multiplication
- 16 times faster division
-
8-bit FAST Microcontroller
- FAST architecture, 4 times faster than the original implementation
- Software compatible with 68HC11 industry standard
- 10 times faster multiplication
- 16 times faster division