ARM big.LITTLE IP
Filter
Compare
7
IP
from
2
vendors
(1
-
7)
-
Arm Cortex-A76
- Better experience, user responsiveness, new ML/AI applications and virtual experiences.
- Brings the always-on functionality of mobile to large screen devices, extending battery life for longer experiences.
- 4x performance for inference ML at the edge.

-
Arm Cortex-A73
- Efficient Out-of-Order Pipeline - Microarchitecture performance and power improvements to maximize efficiency of the 2-wide out-of-order pipeline. Achieve highest peak and sustained performance at frequencies up to 2.8GHz in advanced process technology for Premium smartphones.
- State-of-the-art Branch Prediction and Power-Optimized Instruction Fetching - Advanced sophisticated prediction algorithm with power-optimized 64kB instruction cache.
- High-performance Memory System - Full out-of-order dual-issue load/store capability combined with up to 64kB data cache. Enhanced data prefetching with automatic complex pattern detection.
- Optimized mobile and consumer feature set - Combined with Cortex-A53 or Cortex-35 in big.LITTLE configuration using Arm CCI interconnect for high scalability.

-
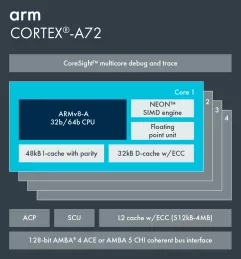
Arm Cortex-A72
- Triple-Issue Out-of-Order Pipeline - Dispatch and computational bandwidth improvements over Cortex-A57 have maximize the effectiveness of the triple-issue out-of-order pipeline to remove code dependencies for achieving high peak and sustained instruction throughputs at frequencies above 3GHz in 16FF+ process technology.
- Advanced Branch Predictor - A sophisticated new algorithm drastically improves prediction accuracy which reduces wasted energy consumption from executing down a wrong code path.
- Microarchitecture Efficiency - Every aspect of the Cortex-A57 microarchitecture was optimized to usher in a new level of Cortex-A energy efficiency with dramatic improvements in all aspects of PPA metrics (performance, power, and area).
- Infrastructure Features - Support for networking and storage application with full ECC cache and 44-bit addressing up to 16TB.
-
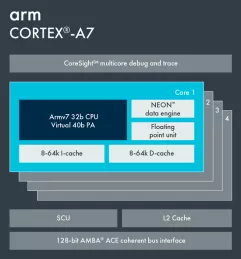
Arm Cortex-A7
- In-order 8 stage pipeline - Improved dual issue, branch prediction and memory system performance. It features 64-bit load-store path, 128-bit AMBA 4 AXI buses and increased TLB size (256 entry).
- Integrated, Configurable Size Level 2 Cache Controller - Provides low-latency and high-bandwidth access to up to 1MB of cached memory in high-frequency designs, or designs needing to reduce the power consumption associated with off-chip memory access. The L2 cache is optional on Cortex-A7.
- Support Armv7-A extensions - Hardware Virtualization and Large Physical Address Extensions (LPAE) enables the processor to access up to 1TB of memory.
- big.LITTLE technology - First LITTLE processor architecturally compatible with compatible with Cortex-A15 and Cortex-A17 for various big.LITTLE processor combinations.
-
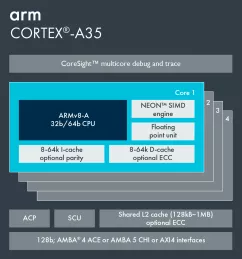
Arm Cortex-A35
- Supports full Armv8-A architecture - Smallest, lowest power and most efficient Armv8-A processor. The Cortex-A35 processor is the most cost effective Armv8-A solution with 64-bit support in AArch64 execution state and seamless backwards compatibility with Armv7-A software in the AArch32 execution state.
- New power management features - Incorporates new power management features compared to the Cortex-A7 processor thereby providing more capabilities to reduce idle power consumption that result in improved battery life for next generation solutions.
- Scalable and versatile - Cortex-A35 processor can be configured from an single core configuration to up to four cores in a single CPU cluster. Being architecturally compatible with existing Armv8-A processors, it can also be connected as a LITTLE CPU in a big.LITTLE system.
-
Arm Cortex-A55
- Superior efficiency
- New memory subsystem
- State-of-the-art architecture
- DynamIQ big.LITTLE

-
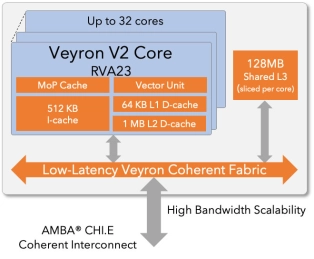
High-performance RISC-V CPU
- Fully compliant with the RVA23 RISC-V specification
- Comparable PPA to Arm Neoverse V3 / Cortex-X4
- Standard AMBA CHI.E coherent interface for SoC and chiplet integration
- Co-architected with Veyron E2 for seamless vector, AI acceleration, and big-little style heterogeneous compute configurations