AI accelerator IP
Filter
Compare
74
IP
from
35
vendors
(1
-
10)
-
RISC-V-Based, Open Source AI Accelerator for the Edge
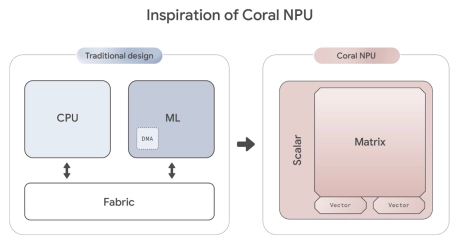
- Coral NPU is a machine learning (ML) accelerator core designed for energy-efficient AI at the edge.
- Based on the open hardware RISC-V ISA, it is available as validated open source IP, for commercial silicon integration.
-
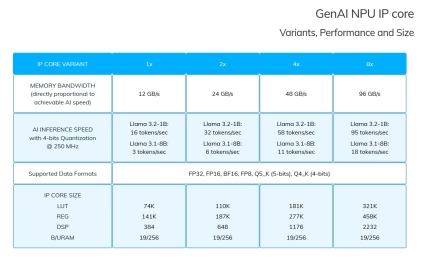
Embedded AI accelerator IP
- The GenAI IP is the smallest version of our NPU, tailored to small devices such as FPGAs and Adaptive SoCs, where the maximum Frequency is limited (<=250 MHz) and Memory Bandwidth is lower (<=100 GB/s).
-
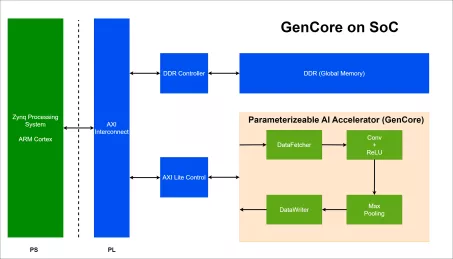
AI Accelerator Specifically for CNN
- A specialized hardware with controlled throughput and hardware cost/resources, utilizing parameterizeable layers, configurable weights, and precision settings to support fixed-point operations.
- This hardware aim to accelerate inference operations, particulary for CNNs such as LeNet-5, VGG-16, VGG-19, AlexNet, ResNet-50, etc.
-
Low power AI accelerator
- Complete speech processing at less than 100W
- Able to run time series nerworks for signal and speech
- 10X more efficient than traditional NNs
-
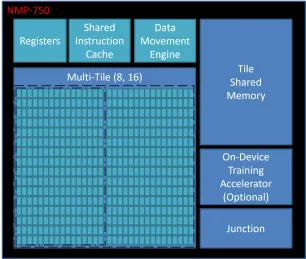
Performance AI Accelerator for Edge Computing
- Up to 16 TOPS
- Up to 16 MB Local Memory
- RISC-V/Arm Cortex-R or A 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
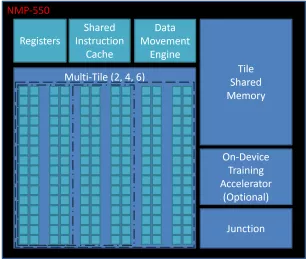
Performance Efficiency AI Accelerator
- Up to 6 TOPS
- Up to 6 MB Local Memory
- RISC-V/Arm Cortex-M or A 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
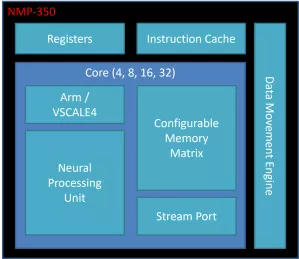
Lowest Power and Cost End Point AI Accelerator
- Up to 1 TOPS
- Up to 1 MB Local Memory
- RISC-V/Arm Cortex-M 32-bit CPU
- 3 x AXI4, 128b (Host, CPU & Data)
-
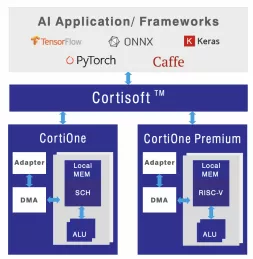
AI Processor Accelerator
- Universal Compatibility: Supports any framework, neural network, and backbone.
- Large Input Frame Handling: Accommodates large input frames without downsizing.
-
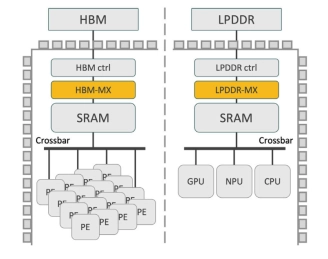
High-Performance Memory Expansion IP for AI Accelerators
- Expand Effective HBM Capacity by up to 50%
- Enhance AI Accelerator Throughput
- Boost Effective HBM Bandwidth
- Integrated Address Translation and memory management:
-
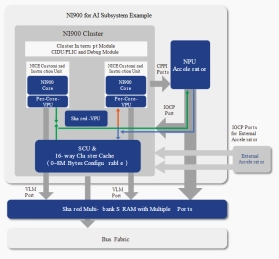
AI DSA Processor - 9-Stage Pipeline, Dual-issue
- NI900 is a DSA processor based on 900 Series.
- NI900 is optimized with features specifically targeting AI applications.