AI Inference Processor IP
Filter
Compare
27
IP
from
14
vendors
(1
-
10)
-
AI inference processor IP
- High Performance, Low Power Consumption, Small Foot Print IP for Deep Learning inference processing.
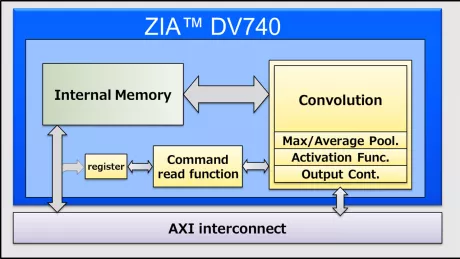
-
Dataflow AI Processor IP
- Revolutionary dataflow architecture optimized for AI workloads with spatial compute arrays, intelligent memory hierarchies, and runtime reconfigurable elements
-
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
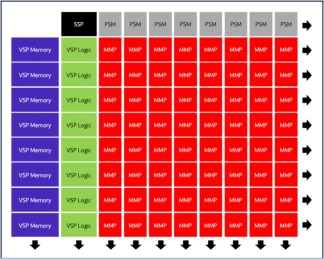
-
Highly Scalable and Efficient Second-Generation ML Inference Processor
- Increased Performance
- Improved Efficiency
- Extended Configurability
-
High-Efficiency, Low-Area ML Inference Processor
- High Efficiency
- Lowest Area
- Optimized Design
- Futureproof
-
ML Inference Processor with Balanced Efficiency and Performance
- Balanced Performance
- Optimized Design
- High Efficiency
-
Low-power high-speed reconfigurable processor to accelerate AI everywhere.
- Multi-Core Number: 4
- Performance (INT8, 600MHz): 0.6TOPS
- Achievable Clock Speed (MHz): 600 (28nm)
- Synthesis Logic Gates (MGates): 2
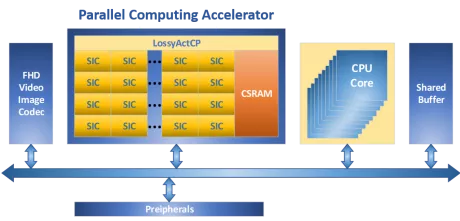
-
Ultra low power inference engine
- Neuromorphic processor
- Sub milliwatt power
- Ultra-low power AI processing
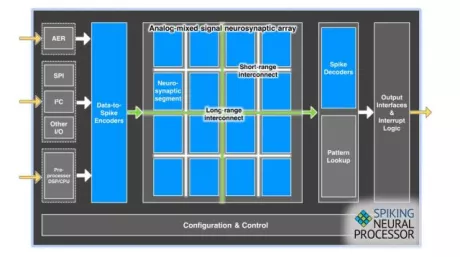
-
Highly scalable inference NPU IP for next-gen AI applications
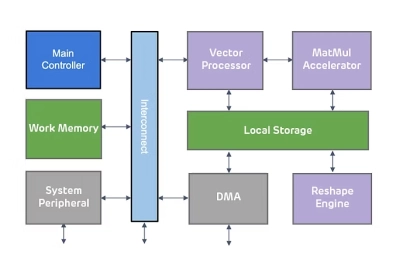
- ENLIGHT Pro is meticulously engineered to deliver enhanced flexibility, scalability, and configurability, enhancing overall efficiency in a compact footprint.
- ENLIGHT Pro supports the transformer model, a key requirement in modern AI applications, particularly Large Language Models (LLMs). LLMs are instrumental in tasks such as text recognition and generation, trained using deep learning techniques on extensive datasets.
-
Safety Enhanced GPNPU Processor IP
- A True SDV Solution
- Fully programmable – ideal for long product life cycles
- Scalable multicore solutions up to 864 TOPS
- Solutions for ADAS, IVI and ECU products