automotive NPU IP
Filter
Compare
22
IP
from
7
vendors
(1
-
10)
-
NPU IP Core for Automotive
- Origin Evolution™ for Automotive offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks.
- Featuring a hardware and software co-designed architecture, Origin Evolution for Automotive scales to 96 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
-
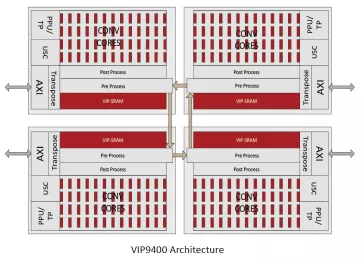
NPU IP for Data Center and Automotive
- 128-bit vector processing unit (shader + ext)
- OpenCL 1.2 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b in PPU
- Convolution layers
-
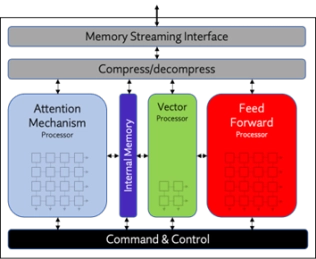
Highly scalable inference NPU IP for next-gen AI applications
- ENLIGHT Pro is meticulously engineered to deliver enhanced flexibility, scalability, and configurability, enhancing overall efficiency in a compact footprint.
- ENLIGHT Pro supports the transformer model, a key requirement in modern AI applications, particularly Large Language Models (LLMs). LLMs are instrumental in tasks such as text recognition and generation, trained using deep learning techniques on extensive datasets.
-
ARC NPX Neural Processing Unit (NPU) IP supports the latest, most complex neural network models and addresses demands for real-time compute with ultra-low power consumption for AI applications
- ARC processor cores are optimized to deliver the best performance/power/area (PPA) efficiency in the industry for embedded SoCs. Designed from the start for power-sensitive embedded applications, ARC processors implement a Harvard architecture for higher performance through simultaneous instruction and data memory access, and a high-speed scalar pipeline for maximum power efficiency. The 32-bit RISC engine offers a mixed 16-bit/32-bit instruction set for greater code density in embedded systems.
- ARC's high degree of configurability and instruction set architecture (ISA) extensibility contribute to its best-in-class PPA efficiency. Designers have the ability to add or omit hardware features to optimize the core's PPA for their target application - no wasted gates. ARC users also have the ability to add their own custom instructions and hardware accelerators to the core, as well as tightly couple memory and peripherals, enabling dramatic improvements in performance and power-efficiency at both the processor and system levels.
- Complete and proven commercial and open source tool chains, optimized for ARC processors, give SoC designers the development environment they need to efficiently develop ARC-based systems that meet all of their PPA targets.
-
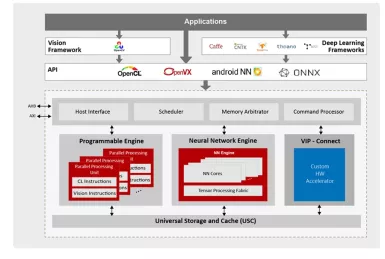
NPU IP for AI Vision and AI Voice
- 128-bit vector processing unit (shader + ext)
- OpenCL 3.0 shader instruction set
- Enhanced vision instruction set (EVIS)
- INT 8/16/32b, Float 16/32b
-
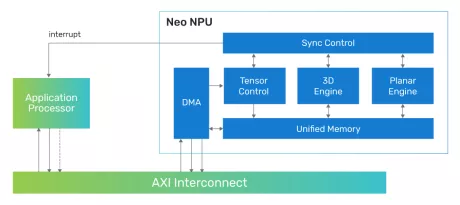
Highly scalable performance for classic and generative on-device and edge AI solutions
- Flexible System Integration: The Neo NPUs can be integrated with any host processor to offload the AI portions of the application
- Scalable Design and Configurability: The Neo NPUs support up to 80 TOPS with a single-core and are architected to enable multi-core solutions of 100s of TOPS
- Efficient in Mapping State-of-the-Art AI/ML Workloads: Best-in-class performance for inferences per second with low latency and high throughput, optimized for achieving high performance within a low-energy profile for classic and generative AI
- Industry-Leading Performance and Power Efficiency: High Inferences per second per area (IPS/mm2 and per power (IPS/W)
-
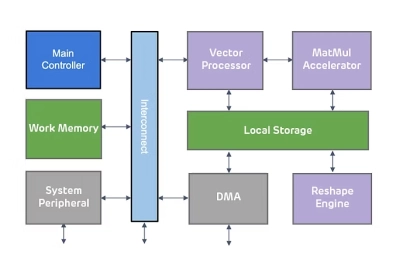
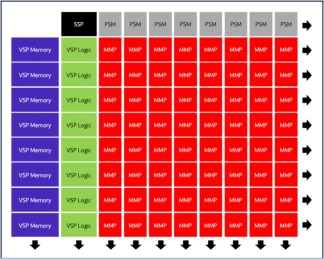
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
-
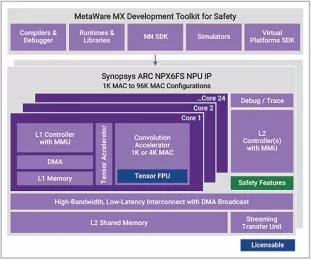
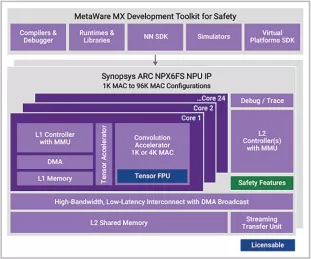
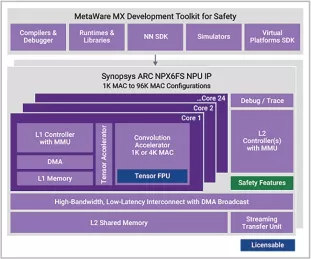
Enhanced Neural Processing Unit for safety providing 98,304 MACs/cycle of performance for AI applications
- Adds hardware safety features to NPX6 NPU, minimizing area and power impact
- Supports ISO 26262 automotive safety standard
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc
- IP targets ASIL B and ASIL D compliance to ISO 26262
-
Enhanced Neural Processing Unit for safety providing 8,192 MACs/cycle of performance for AI applications
- Adds hardware safety features to NPX6 NPU, minimizing area and power impact
- Supports ISO 26262 automotive safety standard
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc
- IP targets ASIL B and ASIL D compliance to ISO 26262
-
Enhanced Neural Processing Unit for safety providing 65,536 MACs/cycle of performance for AI applications
- Adds hardware safety features to NPX6 NPU, minimizing area and power impact
- Supports ISO 26262 automotive safety standard
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc
- IP targets ASIL B and ASIL D compliance to ISO 26262