Tensilica AI IP
Filter
Compare
10
IP
from
1
vendors
(1
-
10)
-
Tensilica DSP IP supports efficient AI/ML processing
- Powerful DSP Instruction Set Supporting AI/ML Operations.
- Mixed Workloads.
- Industry-Leading Performance and Power Efficiency.
- End-to-End Software Toolchain for All Markets and a Large Number of Frameworks.
-
Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints
- Best-in-Class Energy
- Enables Compelling Use Cases and Advanced Concurrency
- Scalable IP for Various Workloads
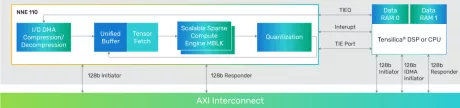
-
Tensilica AI Max - NNA 110 Single Core
- Scalable Design to Adapt to Various AI Workloads
- Efficient in Mapping State-of-the-Art DL/AI Workloads
- End-to-End Software Toolchain for All Markets and Large Number of Frameworks
-
Tensilica Vision P6 DSP
- 1024/512b Load/Store capabilities
- 256 8-bit MAC
- 8/16/32-bit fixed-point processing
- Single-precision (FP32) and half-precision (FP16) floating-point processing
-
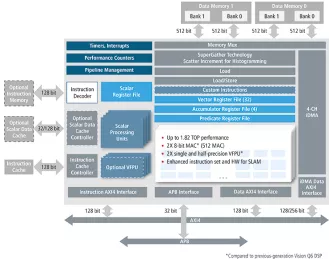
Tensilica Vision Q8 DSP
- 2048/1024b Load/Store capabilities
- 1024 8-bit MAC: 2X MAC capability versus Vision Q7 DSP
- 8/16/32-bit fixed-point processing
- Double-precision (FP64), single-precision (FP32), and half-precision (FP16) floating-point processing
-
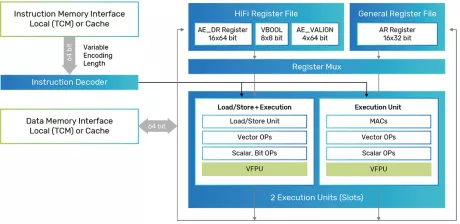
Tensilica HiFi 1 DSP
- Cycle and energy efficient for Bluetooth and Bluetooth Low Energy (BLE) codecs for speech and music
- Efficient neural network acceleration ISA and architecture support
-
Tensilica Vision Q7 DSP
- Doubles Vision and AI Performance for Automotive, AR/VR, Mobile and Surveillance Markets
-
Tensilica HiFi 5 DSP
- Five very long instruction word (VLIW)-slot architecture capable of issuing two 128-bit loads per cycle
-
Tensilica FloatingPoint KQ7/KQ8 DSPs
- VLIW parallelism issuing multiple concurrent operations per cycle
- 512-bit and 1024-bit SIMD
- IEEE 754 vector floating-point (HP, SP, DP)
- Performance-optimized fused multiply-add (FMA)
-
Tensilica FloatingPoint KP1/KP6 DSPs
- VLIW parallelism issuing multiple concurrent operations per cycle
- Xtensa LX Secure Mode
- 128-bit and 512-bit SIMD
- IEEE 754 vector floating-point