Neural Network Engine IP
Filter
Compare
57
IP
from
17
vendors
(1
-
10)
-
Compact neural network engine offering scalable performance (32, 64, or 128 MACs) at very low energy footprints
- Best-in-Class Energy
- Enables Compelling Use Cases and Advanced Concurrency
- Scalable IP for Various Workloads
-
ARC NPX Neural Processing Unit (NPU) IP supports the latest, most complex neural network models and addresses demands for real-time compute with ultra-low power consumption for AI applications
- ARC processor cores are optimized to deliver the best performance/power/area (PPA) efficiency in the industry for embedded SoCs. Designed from the start for power-sensitive embedded applications, ARC processors implement a Harvard architecture for higher performance through simultaneous instruction and data memory access, and a high-speed scalar pipeline for maximum power efficiency. The 32-bit RISC engine offers a mixed 16-bit/32-bit instruction set for greater code density in embedded systems.
- ARC's high degree of configurability and instruction set architecture (ISA) extensibility contribute to its best-in-class PPA efficiency. Designers have the ability to add or omit hardware features to optimize the core's PPA for their target application - no wasted gates. ARC users also have the ability to add their own custom instructions and hardware accelerators to the core, as well as tightly couple memory and peripherals, enabling dramatic improvements in performance and power-efficiency at both the processor and system levels.
- Complete and proven commercial and open source tool chains, optimized for ARC processors, give SoC designers the development environment they need to efficiently develop ARC-based systems that meet all of their PPA targets.
-
PowerVR Neural Network Accelerator - The ultimate solution for high-end neural networks acceleration
- Security
- Lossless weight compression
-
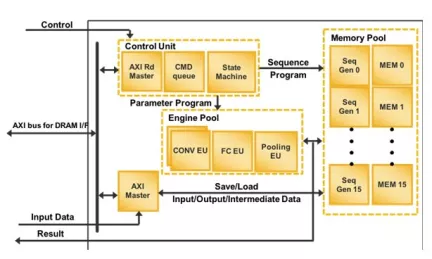
DPU for Convolutional Neural Network
- Configurable hardware architecture
- Configurable core number up to three
- Convolution and deconvolution
-
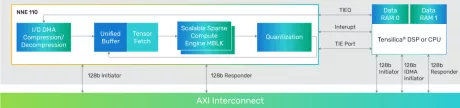
Run-time Reconfigurable Neural Network IP
- Customizable IP Implementation: Achieve desired performance (TOPS), size, and power for target implementation and process technology
- Optimized for Generative AI: Supports popular Generative AI models including LLMs and LVMs
- Efficient AI Compute: Achieves very high AI compute utilization, resulting in exceptional energy efficiency
- Real-Time Data Streaming: Optimized for low-latency operations with batch=1

-
Convolutional Neural Network (CNN) Compact Accelerator
- Support convolution layer, max pooling layer, batch normalization layer and full connect layer
- Configurable bit width of weight (16 bit, 1 bit)
-
Power efficient, high-performance neural network hardware IP for automotive embedded solutions
- Power efficient, high-performance
- For automotive embedded solutions
-
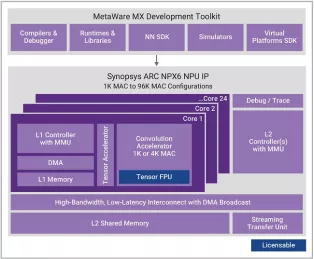
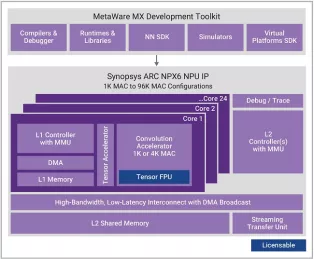
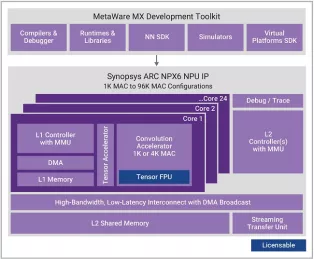
Enhanced Neural Processing Unit providing 98,304 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
Enhanced Neural Processing Unit providing 8,192 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator
-
Enhanced Neural Processing Unit providing 65,536 MACs/cycle of performance for AI applications
- Scalable real-time AI / neural processor IP with up to 3,500 TOPS performance
- Supports CNNs, transformers, including generative AI, recommender networks, RNNs/LSTMs, etc.
- Industry leading power efficiency (up to 30 TOPS/W)
- One 1K MAC core or 1-24 cores of an enhanced 4K MAC/core convolution accelerator