Machine Learning Processor IP
Filter
Compare
47
IP
from
21
vendors
(1
-
10)
-
Machine Learning Processor
- Extending Performance and Efficiency
- Flexible Integration
- Unified Software and Tools
-
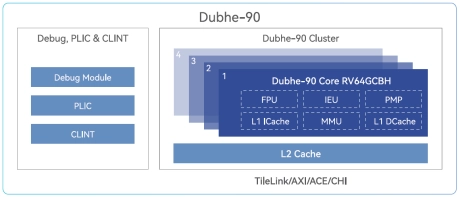
High Performance 64-bit RISC-V Processor
- Dubhe-90 is a high-performance commercial RISC-V CPU Core IP that is deliverable.
- It adopts an 11+ stage and 5-issue pipeline, superscalar, and deep out-of-order execution, and supports standard RISC-V RV64GCBH extensions.
-
Safety Enhanced GPNPU Processor IP
- A True SDV Solution
- Fully programmable – ideal for long product life cycles
- Scalable multicore solutions up to 864 TOPS
- Solutions for ADAS, IVI and ECU products
-
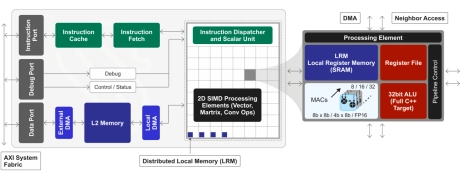
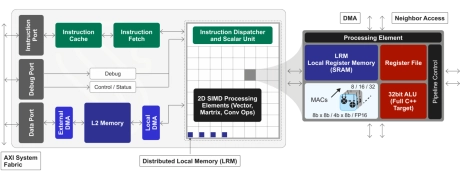
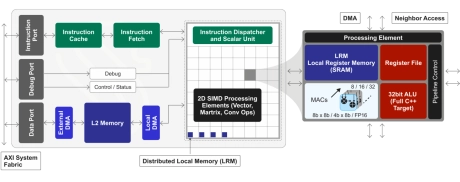
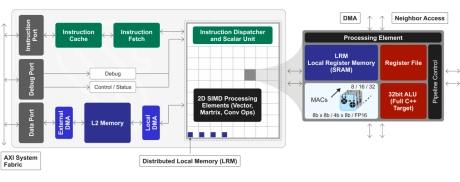
GPNPU Processor IP - 32 to 864TOPs
- 32 to 864TOPs
- (Dual, Quad, Octo Core) Up to 256K MACs
- Hybrid Von Neuman + 2D SIMD matrix architecture
- 64b Instruction word, single instruction issue per clock
- 7-stage, in-order pipeline
- Scalar / vector / matrix instructions modelessly intermixed with granular predication
-
-
-
-
All-analog Neural Signal Processor
- Analog AI Innovation: Blumind AMPL™ is a disruptive analog AI compute fabric for micropower artificial intelligence applications.
- Precision and Accuracy: Blumind all-analog AI compute delivers deterministic and precise inferencing performance at up to x1000 lower power than our competitors. Delivering higher efficiency and the longest battery life for always-on applications.
- Low Latency Solutions: AMPL™ fabric delivers efficient low latency for real-time applications.
- Analog Breakthrough: AMPL™ is the first all-analog AI on advanced standard CMOS architected to fundamentally mitigate process, voltage, temperature and drift variations.