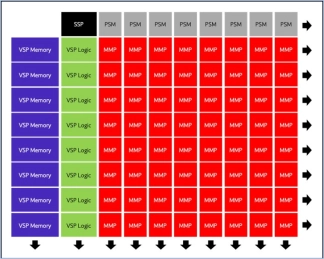
CNN accelerator IP
Filter
Compare
9
IP
from
6
vendors
(1
-
9)
-
Convolutional Neural Network (CNN) Compact Accelerator
- Support convolution layer, max pooling layer, batch normalization layer and full connect layer
- Configurable bit width of weight (16 bit, 1 bit)
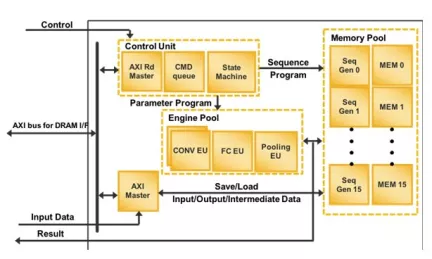
-
AI Accelerator Specifically for CNN
- A specialized hardware with controlled throughput and hardware cost/resources, utilizing parameterizeable layers, configurable weights, and precision settings to support fixed-point operations.
- This hardware aim to accelerate inference operations, particulary for CNNs such as LeNet-5, VGG-16, VGG-19, AlexNet, ResNet-50, etc.
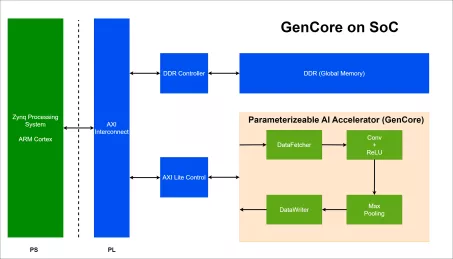
-
High performance-efficient deep learning accelerator for edge and end-point inference
- Configurable MACs from 32 to 4096 (INT8)
- Maximum performance 8 TOPS at 1GHz
- Configurable local memory: 16KB to 4MB
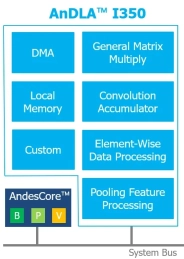
-
Accelerator for Convolutional Neural Networks
- Include VGG, ResNet, MobileNet, and other custom use cases.
-
Neural engine IP - Tiny and Mighty
- The Origin E1 NPUs are individually customized to various neural networks commonly deployed in edge devices, including home appliances, smartphones, and security cameras.
- For products like these that require dedicated AI processing that minimizes power consumption, silicon area, and system cost, E1 cores offer the lowest power consumption and area in a 1 TOPS engine.
-
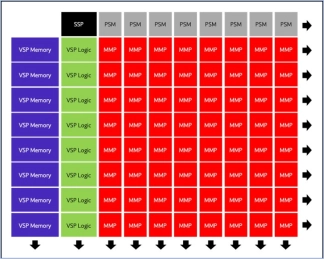
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
-
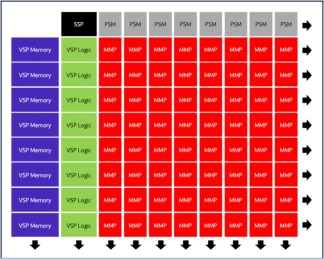
Neural engine IP - The Cutting Edge in On-Device AI
- The Origin E6 is a versatile NPU that is customized to match the needs of next-generation smartphones, automobiles, AV/VR, and consumer devices.
- With support for video, audio, and text-based AI networks, including standard, custom, and proprietary networks, the E6 is the ideal hardware/software co-designed platform for chip architects and AI developers.
- It offers broad native support for current and emerging AI models, and achieves ultra-efficient workload scheduling and memory management, with up to 90% processor utilization—avoiding dark silicon waste.
-
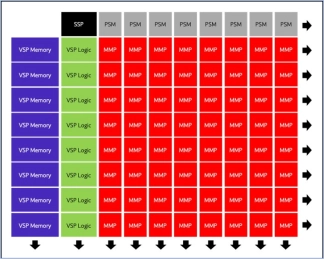
Neural engine IP - Balanced Performance for AI Inference
- The Origin™ E2 is a family of power and area optimized NPU IP cores designed for devices like smartphones and edge nodes.
- It supports video—with resolutions up to 4K and beyond— audio, and text-based neural networks, including public, custom, and proprietary networks.