AI Inference IP
Filter
Compare
42
IP
from
23
vendors
(1
-
10)
-
AI inference engine for real-time edge intelligence
- Flexible Models: Bring your physical AI application, open-source, or commercial model
- Easy Adoption: Based on open-specification RISC-V ISA for driving innovation and leveraging the broad community of open-source and commercial tools
- Scalable Design: Turnkey enablement for AI inference compute from 10’s to 1000’s of TOPS
-
AI inference engine for Audio
- The TimbreAI™ is an ultra-low-power AI Interface engine designed for audio noise reduction use cases in consumer devices such as wireless headsets.
- It provides optimal performance within strict power and area constraints. Featuring 3.2 billion operations per second (GOPS) performance, the TimbreAI T3 sips an astonishingly low 300µW or less power.
- TimbreAI supports quick and seamless deployments. It is available as soft IP and is portable to any foundry silicon process.
-
Neural engine IP - AI Inference for the Highest Performing Systems
- The Origin E8 is a family of NPU IP inference cores designed for the most performance-intensive applications, including automotive and data centers.
- With its ability to run multiple networks concurrently with zero penalty context switching, the E8 excels when high performance, low latency, and efficient processor utilization are required.
- Unlike other IPs that rely on tiling to scale performance—introducing associated power, memory sharing, and area penalties—the E8 offers single-core performance of up to 128 TOPS, delivering the computational capability required by the most advanced LLM and ADAS implementations.
-
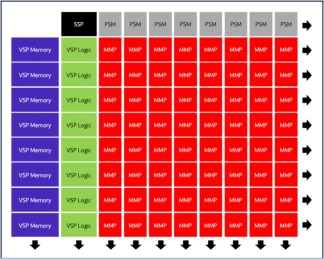
Neural engine IP - Balanced Performance for AI Inference
- The Origin™ E2 is a family of power and area optimized NPU IP cores designed for devices like smartphones and edge nodes.
- It supports video—with resolutions up to 4K and beyond— audio, and text-based neural networks, including public, custom, and proprietary networks.
-
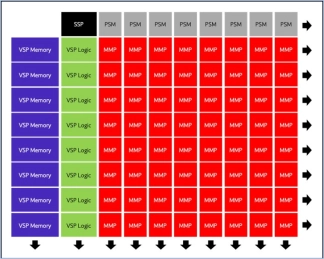
AI inference processor IP
- High Performance, Low Power Consumption, Small Foot Print IP for Deep Learning inference processing.
-
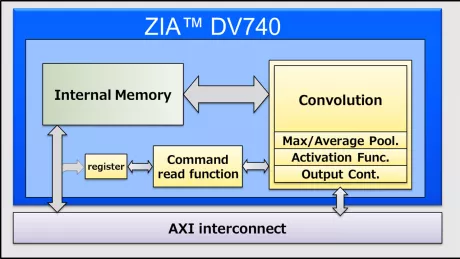
Highly scalable inference NPU IP for next-gen AI applications
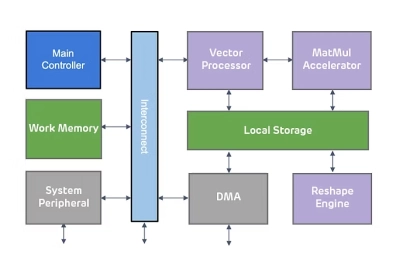
- ENLIGHT Pro is meticulously engineered to deliver enhanced flexibility, scalability, and configurability, enhancing overall efficiency in a compact footprint.
- ENLIGHT Pro supports the transformer model, a key requirement in modern AI applications, particularly Large Language Models (LLMs). LLMs are instrumental in tasks such as text recognition and generation, trained using deep learning techniques on extensive datasets.
-
Dataflow AI Processor IP
- Revolutionary dataflow architecture optimized for AI workloads with spatial compute arrays, intelligent memory hierarchies, and runtime reconfigurable elements
-
RISC-V AI Acceleration Platform - Scalable, standards-aligned soft chiplet IP
- Built on RISC-V and delivered as soft chiplet IP, the Veyron E2X provides scalable, standards-based AI acceleration that customers can integrate and customize freely.

-
AI SDK for Ceva-NeuPro NPUs
- Ceva-NeuPro Studio is a comprehensive software development environment designed to streamline the development and deployment of AI models on the Ceva-NeuPro NPUs.
- It offers a suite of tools optimized for the Ceva NPU architectures, providing network optimization, graph compilation, simulation, and emulation, ensuring that developers can train, import, optimize, and deploy AI models with highest efficiency and precision.
-
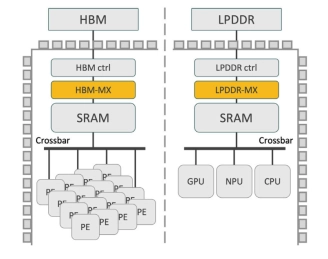
High-Performance Memory Expansion IP for AI Accelerators
- Expand Effective HBM Capacity by up to 50%
- Enhance AI Accelerator Throughput
- Boost Effective HBM Bandwidth
- Integrated Address Translation and memory management: