Ceva-NeuPro-Nano is a highly efficient, self-sufficient Edge NPU designed for TinyML applications. It delivers the optimal balance of ultra-low power and the best performance in a small area to efficiently execute TinyML workloads across AIoT product categories, including Hearables, Wearables, Home Audio, Smart Home, Smart Factory, and more. Ranging from 10 GOPS up to 200 GOPS per core, Ceva-NeuPro-Nano is designed to enable always-on use-cases on battery-operated devices, integrating voice, vision, and sensing use cases across a wide array of end markets. Bringing the possibilities enabled by TinyML into a reality for low cost, energy efficient AIoT devices.
Ceva-NeuPro-Nano is not an AI accelerator and does not require a host CPU/DSP to operate. However, it includes all the processing elements of a standalone NPU, including code execution and memory management. The Ceva-NeuPro-Nano embedded AI NPU architecture is fully programmable and efficiently executes Neural Networks, feature extraction, control code and DSP code, and supports most advanced machine learning data types and operators including native transformer computation, sparsity acceleration and fast quantization. This optimized, self-sufficient architecture enables Ceva-NeuPro-Nano NPUs to deliver superior power efficiency, with a smaller silicon footprint, and optimal performance compared to the existing processor solutions used for TinyML workloads which utilize a combination of CPU or DSP with AI accelerator-based architectures.
NPU IP for Embedded AI
Overview
Key Features
- Fully programmable to efficiently execute Neural Networks, feature extraction, signal processing, audio and control code
- Scalable performance by design to meet wide range of use cases with MAC configurations with up to 64 int8 (native 128 of 4x8) MACs per cycle
- Future proof architecture that supports the most advanced ML data types and operators
- 4-bit to 32-bit integer support
- Native transformer computation
- Ultimate ML performance for all use cases
- Acceleration of sparse model inference (sparsity acceleration)
- Acceleration of non-linear activation types
- Fast quantization – up to 5 times acceleration of internal re-quantizing tasks
- Ultra-low memory requirements achieved with Ceva-NetSqueeze™
- Up to 80% memory footprint reduction through direct processing of compressed model weights without need for intermediate decompression stage
- Solves a key bottleneck inhibiting the broad adoption of AIoT processors today
- Ultra-low energy achieved through innovative energy optimization
- Dynamic Voltage and Frequency Scaling support - tunable for the use-case
- Dramatic energy and bandwidth reduction by distilling computations using weight-sparsity acceleration
- Complete, simple to use Ceva NeuPro-Studio AI SDK
- Optimized to work seamlessly with leading, open-source AI inference frameworks, such as TFLM and µTVM
- Model Zoo of pre-trained and optimized machine learning models covering TinyML voice, vision and sensing use cases.
- Comprehensive portfolio of optimized runtime libraries and off-the-shelf application-specific software
- Two NPU configurations to address a wide variety of use cases
- Ceva-NPN32 with 32 4x8, 32 8x8, 16 16x8, 8 16x16, 4 32x32 MPY/MAC operations per cycle
- Ceva-NPN64 with 128 4x8, 64 8x8, 32 16x8, 16 16x16, 4 32x32 MPY/MAC operations per cycle and 2x performance acceleration using 50% weight sparsity (Sparsity Acceleration)
Benefits
- The NPU family is specially designed to bring the power of AI to the Internet of Things (IoT), through efficient deployment of Tiny Machine Learning (TinyML) models on low-power, resource-constrained devices.
- Fully programmable and efficiently executes Neural Networks, feature extraction, control code and DSP code
- Supports most advanced machine learning data types of 4,8,16, and 32-bit, and many operators including native transformer computation, fast quantization and sparsity support with weight decompression and acceleration
- Self-sufficient architecture enables NPUs to deliver superior power efficiency, with a smaller silicon footprint, and optimal performance
Block Diagram
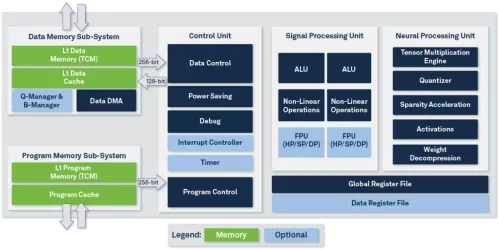
Technical Specifications
Maturity
In Production
Availability
Available
Related IPs
- High-Performance Memory Expansion IP for AI Accelerators
- High Performance Embedded Host NVMe IP Core
- I2C Controller IP – Slave, SCL Clock, Parameterized FIFO, APB Bus. For low power requirements in I2C Slave Controller interface to CPU
- CPU-less QUIC Offload IP core for FPGA Acceleration
- NPU IP for AI Vision and AI Voice
- AI accelerator (NPU) IP - 1 to 20 TOPS