NeuPro-M™ redefines high-performance AI (Artificial Intelligence) processing for smart edge devices and edge compute with heterogeneous coprocessing, targeting generative and classic AI inferencing workloads.
NeuPro-M is a highly power-efficient and scalable NPU architecture with an exceptional power efficiency of up to 350 Tera Ops Per Second per Watt (TOPS/Watt).
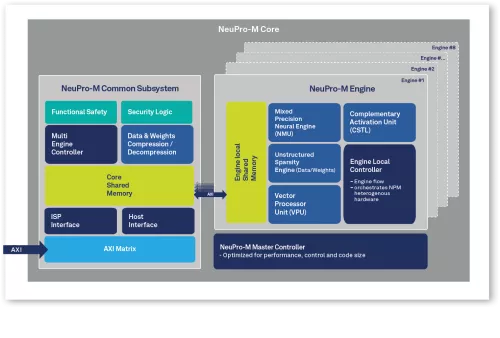
NeuPro-M provides a major leap in performance thanks to its heterogeneous coprocessors that demonstrate compound parallel processing, firstly within each internal processing engine and secondly between the engines themselves.
Ranging from 4 TOPS up to 256 TOPS per core and is fully scalable to reach above 1200 TOPS using multi-core configurations, NeuPro-M can cover a wide range of AI compute application needs which enables it to fit a broad range of end markets including infrastructure, industrial, automotive, PC, consumer, and mobile.
With various orthogonal memory bandwidth reduction mechanisms, decentralized architecture of the NPU management controllers and memory resources, NeuPro-M can ensure full utilization of all its coprocessors while maintaining stable and concurrent data tunneling that eliminate issues of bandwidth limited performance, data congestion or processing unit starvation. These also reduce the dependency on the external memory of the SoC which the NeuPro-M NPU IP is embedded into.
NeuPro-M AI processor builds upon Ceva’s industry-leading position and experience in deep neural networks applications. Dozens of customers are already deploying Ceva’s computer vision & AI platforms along with the full CDNN (Ceva Deep Neural Network) toolchain in consumer, surveillance and ADAS products.
NeuPro-M was designed to meet the most stringent safety and quality compliance standards like automotive ISO 26262 ASIL-B functional safety standard and A-Spice quality assurance standards and comes complete with a full comprehensive AI software stack including:
NeuPro-M system architecture planner tool – Allowing fast and accurate neural network development over NeuPro-M and ensure final product performance
Neural network training optimizer tool allows even further performance boost & bandwidth reduction still in the neural network domain to fully utilize every NeuPro-M optimized coprocessor
CDNN AI compiler & runtime, compose the most efficient flow scheme within the processor to ensure maximum utilization in minimum bandwidth per use-case
Compatibility with common open-source frameworks, including TVM and ONNX
The NeuPro-M NPU architecture supports secure access in the form of optional root of trust, authentication against IP / identity theft, secure boot and end to end data privacy.
NPU IP family for generative and classic AI with highest power efficiency, scalable and future proof
Overview
Key Features
- Support wide range of activations & weights data types, from 32-bit Floating Point down to 2-bit Binary Neural Networks (BNN)
- Unique mixed precision neural engine MAC array micro architecture to support data type diversity with minimal power consumption
- Out-of-the-box, untrained Winograd transform engine that allows to replace traditional convolution methods while using 4-bit, 8-bit, 12-bit or 16-bit weights and activations, increasing efficiency in a factor of 2x with <0.5% precision degradation
- Unstructured Sparsity engine to avoid operations with zero-value weights or activations of every layer along the inference process. With up to 4x in performance, sparsity will also reduce memory bandwidth and power consumption
- Simultaneous processing of the Vector Processing Unit (VPU), a fully programmable processor for handling any future new neural network architectures to come
- Lossless Real-time Weight and Data compression/decompression, for reduced external memory bandwidth
- Scalability by applying different memory configuration per use-case and inherent single core with 1-8 multiengine architecture system for diverse processing performance
- Secure boot and neural network weights/data against identity theft
- 2 degrees of freedom parallel processing
- Memory hierarchy architecture to minimize power consumption attributed to data transfers to and from an external SDRAM as well as optimize overall bandwidth consumption
- Management controllers decentralized architecture with local data controller on each engine to achieve optimized data tunneling for low bandwidth and maximal utilization as well as efficient parallel processing schema
- Supports next generation NN architectures like: fully-connected (FC), FC batch, RNN, transformers (self-attention), 3D convolution and more…
- The NeuPro-M AI processor architecture includes the following processor options:
- NPM11 – A single NPM engine, with processing power of up to 20 TOPS
- NPM18 – An Octa NPM engine, with processing power of up to 160 TOPS
- Matrix Decomposition for up to 10x enhanced performance during network inference
Benefits
- The NeuPro-M family NPU IP for AI processors is designed to reduce the high barriers-to-entry into the AI space in terms of both architecture and software. Enabling an optimized and cost-effective standard AI platform that can be utilized for a multitude of AI-based workloads and applications
- A self-contained heterogeneous AI/ML architecture that concurrently processes diverse workloads of Deep Neural Networks (DNN) using mixed precision MAC array, Winograd engine, Sparsity engine, Vector Processing Unit (VPU), Weight and Data compression
- Scalable performance of 8 to 1,200 TOPS in a modular multi-engine/multi-core architecture at both SoC and Chiplet levels for diverse application needs. Up to 20 TOPS for a single engine NPM core and up to 160TOPS for an Octa engine NPM core
- 5-15X higher performance and 6X bandwidth reduction vs. NeuPro previous generation with overall utilization of more than 90% and outstanding energy efficiency of up to 24 TOPS/Watt
Block Diagram
Technical Specifications
Maturity
In Production
Availability
Available
Related IPs
- GPU IP - Advanced graphics and compute acceleration for power constrained devices
- Highly scalable performance for classic and generative on-device and edge AI solutions
- Fast Quantum Safe Engine for ML-KEM (CRYSTALS-Kyber) and ML-DSA (CRYSTALS-Dilithium) with DPA
- Programmable Root of Trust With DPA and FIA for US Defense
- SATA/SAS 3.0 transceiver IP with PMA and PCS layer
- JESD204B/204C IP with PHY and MAC layer