Accelerating Precise End-to-End Simulation: Latency-Sensitive Many-core System Modeling
By Yinrong Li 1, Zexin Fu 1, Yichao Zhang 1, Germain Haugou 1, Chi Zhang 1, Marco Bertuletti 1, Bowen Wang 1, Luca Benini 1,2
1 Integrated Systems Laboratory (IIS), ETH Zurich, Zurich, Switzerland
2 Department of Electrical, Electronic, and Information Engineering (DEI), University of Bologna, Bologna, Italy
Abstract
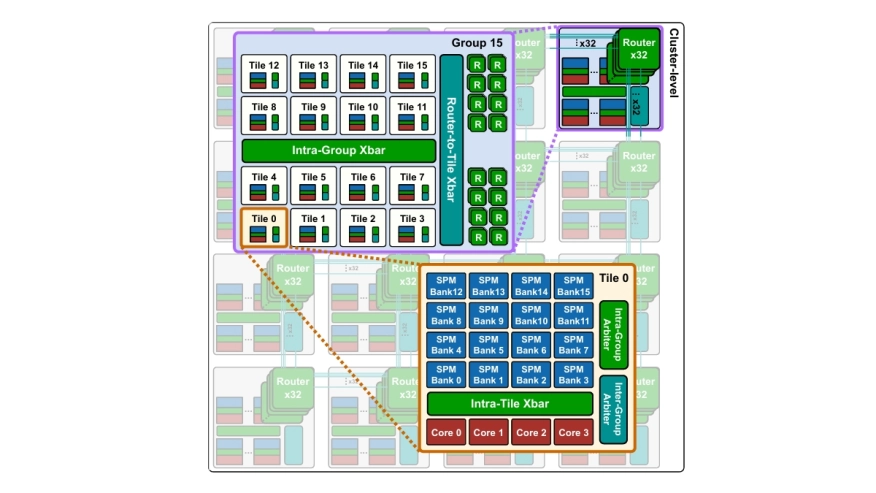
Modern large language model workloads put increasing demands on parallel compute capability and on-chip memory capacity, while also stressing fine-grained data movement and synchronization. These trends motivate exploring and designing many-core accelerators with tightly coupled scratchpad memory (SPM) for scalable compute and predictable, explicitly managed data access. However, this architectural shift raises two challenges: cycle-accurate register-transfer level (RTL) simulation becomes prohibitively slow as system complexity grows, and performance estimation requires precise modeling of latency-sensitive interconnect behavior. This paper presents a fast yet accurate end-to-end modeling approach for latency-sensitive many-core architectures, targeting large-scale instances such as TeraNoC with 1024 cores and a 4MiB globally shared L1 SPM. The approach captures timing behavior of latency-sensitive SPM accesses across multiple interconnect scales, while abstracting non-essential hardware details. Across diverse benchmarks, the model tracks a cycle-accurate RTL golden model with errors below 7%, while delivering up to 115x faster simulation. The framework also provides detailed profiling across processing elements and interconnect, enabling efficient end-to-end software development and hardware design exploration. Two case studies demonstrate its practicality: profiling-guided optimization of FlashAttention-2 to reduce interconnect stalls and synchronization overhead, and design space exploration of network-on-chip (NoC) router remapping to alleviate traffic imbalance and improve throughput.
Index Terms — Simulator, many-core, interconnect
To read the full article, click here
Related Semiconductor IP
- NoC Interconnect IP Generator
- NoC Silicon IP for RISC-V based chips supporting the TileLink protocol
- NoC Verification IP
- FlexGen Smart Network-on-Chip (NoC) IP
- NoC System IP
Related Articles
- MpNoC Design: Modeling and Simulation
- SystemC: Key modeling concepts besides TLM to boost your simulation performance
- Embedded system virtualization for executable specifications and use case modeling
- Comparing AMBA AHB to AXI Bus using System Modeling
Latest Articles
- Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
- Si-GT: Fast Interconnect Signal Integrity Analysis For Integrated Circuit Design Via Graph Transformers
- Hardware Mechanisms to Dynamically Throttle AI Performance
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers