VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
By Zi-Wei Lin, and Tian-Sheuan Chang
Institute of Electronics, National Yang Ming Chiao Tung University, Hsinchu, Taiwan
Abstract
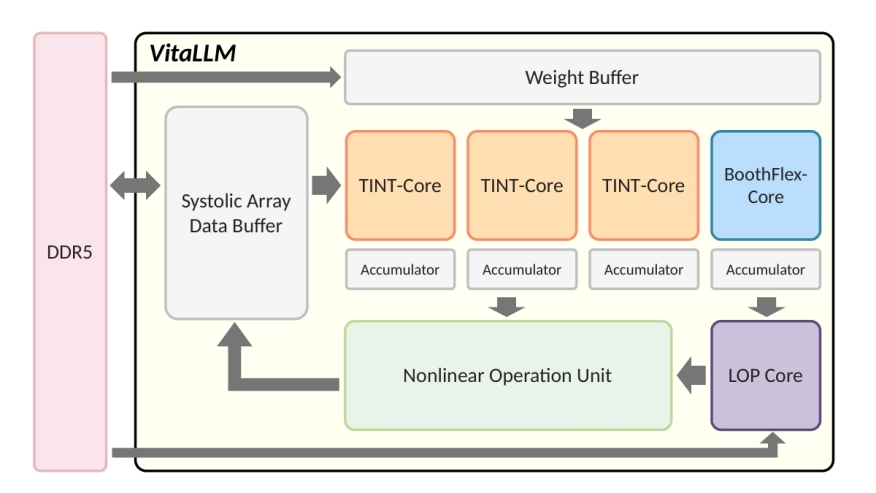
We present VitaLLM, a mixed-precision accelerator that enables ternary-weight large language models to run efficiently on edge devices. The design combines two compute cores—a multiplier-free TINT core for ternary–INT projections and a BoothFlex core that reuses a radix-4 Booth datapath for both INT8×INT8 attention and ternary–INT—sustaining utilization without duplicating arrays. A predictive sparse attention mechanism employs a leading-one (LO) surrogate with a comparison-free top-K selector to prune key/value (KV) fetches by roughly 1−K/M for M cached tokens, confining exact attention to K candidates. System-level integration uses head-level pipelining and an absmax-based quantization barrier to standardize cross-core interfaces and overlap nonlinear reductions with linear tiles. A 16nm silicon prototype at 1GHz/0.8V achieves 72.46 tokens/s in decode and 0.88 s prefill (64 tokens) within 0.214 mm² and 120 KB on-chip memory, while reducing KV traffic and improving utilization in ablations. These results demonstrate practical BitNet b1.58 (3B) inference on edge-class platforms and provide a compact blueprint for future mixed-precision LLM accelerators.
To read the full article, click here
Related Semiconductor IP
- GPU
- V-by-One Verification IP
- AI model compression IP
- Hardware compressed memory IP for CXL devices and chip-to-chip links
- Hardware link (de)compression IP for die-to-die, chip-to-chip, and DRAM interfaces
Related Articles
- FPGA-Accelerated RISC-V ISA Extensions for Efficient Neural Network Inference on Edge Devices
- Heterogeneous SoC Integrating an Open-Source Recurrent SNN Accelerator for Neuromorphic Edge Computing on FPGA
- CD-PIM: A High-Bandwidth and Compute-Efficient LPDDR5-Based PIM for Low-Batch LLM Acceleration on Edge-Device
- LLM Inference with Codebook-based Q4X Quantization using the Llama.cpp Framework on RISC-V Vector CPUs
Latest Articles
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding
- Vectorizing Quantum Control: A RISC-V Vector Extension Architecture for Scalable Qubit Systems
- FlexViT: A Flexible FPGA-based Accelerator for Edge Vision Transformers
- LIB-TRAP: Standard Cell Library Hardware Trojan Risk Assessment and Prevention