Closer in the Gap: Towards Portable Performance on RISC-V Vector Processors
By Ruimin Shi 1, Maya Gokhale 2, Pei-Hung Lin 2, Xavier Teruel 3, and Ivy Peng 1
1 KTH Royal Institute of Technology, Sweden
2 Lawrence Livermore National Laboratory, USA
3 Barcelona Supercomputing Center, Spain
Abstract
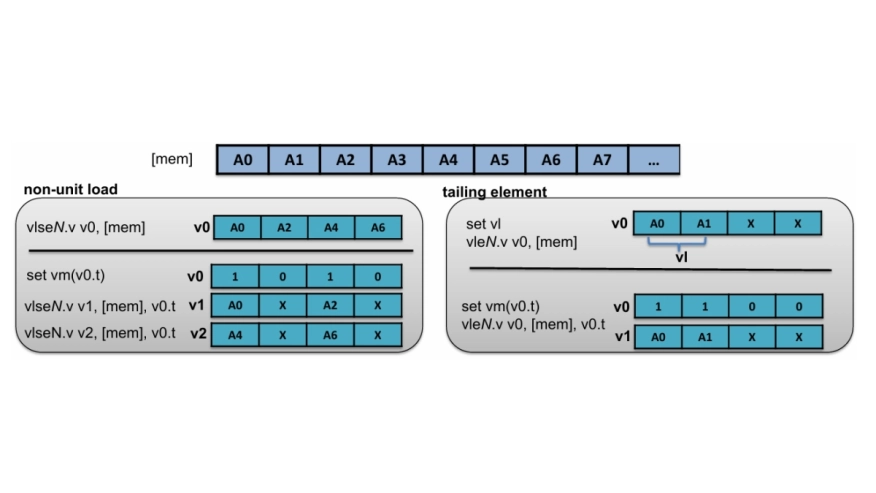
The RISC-V Vector Extension (RVV) is a cornerstone for supporting compute throughout in scientific and machine learning workloads. Yet compiler support and performance monitoring on real RVV 1.0 hardware are still evolving. In this work, we design a suite of assembly microbenchmarks to establish performance ceilings and calibrate performance counters on RVV hardware. Leveraging the assembly bench marks, we find that predication overhead and stride load pose performance challenges that current compiler cost models do not yet fully address. Moreover, we present the first evaluation of GCC 15 and LLVM 21 autovectorization in HPC and ML proxy applications. GCC 15 outper forms LLVM 21 in four out of six applications. LLVM 21 only outperforms GCC 15 in SGEMM and DGEMM, driven by more aggressive instruction reduction confirmed through validated perf counters on the RVV hardware. We further show that the default LMUL selection in compilers performs close to the optimal. To study the RVV support for product-level application, we also evaluate the state-vector quantum sim ulator, Google’s Qsim, with both manual RVV intrinsics and compiler auto-vectorization, revealing immaturity in current RVV compiler for complicated memory access pattern.
To read the full article, click here
Related Semiconductor IP
- Highly efficient out-of-order RISC-V vector application processor series
- High performance dual-issue, out-of-order, 7-stage Vector processor (DSP) IP
- Multi-core capable RISC-V processor with vector extensions
- ARC-V RHX-100 dual-issue, 32-bit single-core RISC-V processor for real-time applications
- ARC-V RHX-105 dual-issue, 32-bit RISC-V processor for real-time applications (multi-core)
Related Articles
- Microarchitectural Co-Optimization for Sustained Throughput of RISC-V Multi-Lane Chaining Vector Processors
- Performance Optimization of Embedded Software for ARM Processors and AMBA Methodology-based Systems
- Hit performance goals with configurable processors
- Performance Evaluation of Inter-Processor Communication Mechanisms on the Multi-Core Processors using a Reconfigurable Device
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding