TTP: A Hardware-Efficient Design for Precise Prefetching in Ray Tracing
By Yavuz Selim Tozlu, Anshul Naithani, Huiyang Zhou
North Carolina State University, Raleigh, USA
Abstract
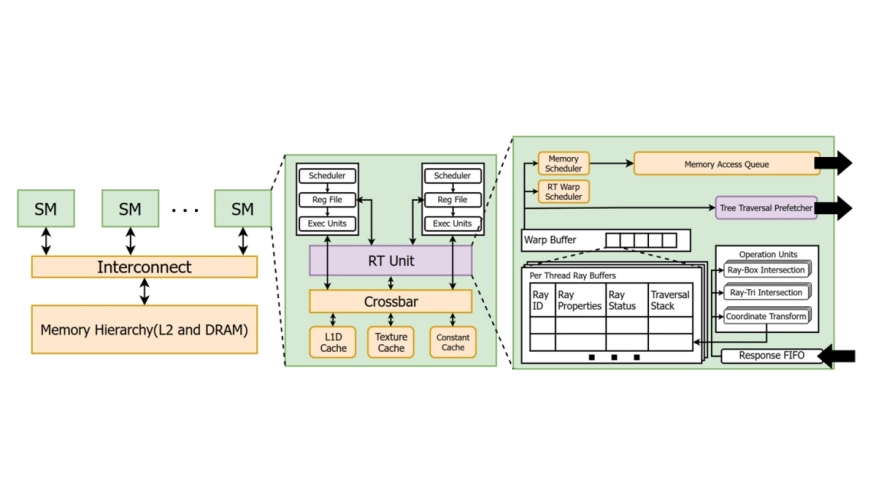
Ray tracing (RT) is a 3D graphics technique that offers highly realistic visuals. It is becoming prominent and accessible as GPU vendors have integrated dedicated ray tracing acceleration hardware. However, tracing millions of rays through 3D scenes consisting of high numbers of triangles in real time is challenging and requires expensive hardware. The main bottleneck in RT workloads is the expensive Bounding Volume Hierarchy (BVH) traversal task, which is a large tree structure that encodes the 3D scene. BVH traversal is a memory-bound problem, as the GPU threads spend most of their time reading tree node data from memory.
In this work, we attack the memory latency bottleneck of ray tracing through prefetching. We propose a novel hardware prefetcher, named Tree Traversal Prefetcher (TTP), for ray tracing. The main idea is to leverage the existing tree traversal stack in the RT units for highly accurate prefetching. In particular, TTPprefetches nodes using the addresses already available on the hardware traversal stacks of each thread. For DFS (Depth-first search) based traversal, prefetches are generated when nodes are being popped consecutively from the traversal stack, potentially corresponding to upward traversal through the tree.
We evaluate TTP on a cycle-level simulator, Vulkan-sim 2.0, and show that it achieves 1.48x speedup on average (up to 1.89x) compared to the baseline, with nearly negligible hardware overhead. TTP achieves 98.92% average L1 accuracy, which is the ratio of the prefetched blocks being actually referenced by demand loads. The coverage, computed as the ratio of L1 miss reduction over baseline L1 misses, is 31.54%, correlating well with the achieved speedup.
Index Terms — GPU, Ray Tracing, Prefetching.
To read the full article, click here
Related Semiconductor IP
- Ray tracing GPU
- Mobile GPU core with ray tracing
- Real-Time Ray Tracing GPU
- Arm’s flagship GPU providing ultimate mobile gaming experiences
- Arm's most performance and efficient GPU till date, offering unparalled mobile gaming and ML performance
Related Articles
- ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
- It's Just a Jump to the Left, Right? Shift Left in IC Design Enablement
- Customizing a Large Language Model for VHDL Design of High-Performance Microprocessors
- Physical Design Exploration of a Wire-Friendly Domain-Specific Processor for Angstrom-Era Nodes
Latest Articles
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding
- Vectorizing Quantum Control: A RISC-V Vector Extension Architecture for Scalable Qubit Systems
- FlexViT: A Flexible FPGA-based Accelerator for Edge Vision Transformers
- LIB-TRAP: Standard Cell Library Hardware Trojan Risk Assessment and Prevention