Breaking the HBM Bit Cost Barrier: Domain-Specific ECC for AI Inference Infrastructure
By Rui Xie †, Asad Ul Haq †, Yunhua Fang †, Linsen Ma †, Sanchari Sen ∗, Swagath Venkataramani ∗, Liu Liu †, Tong Zhang †
† Rensselaer Polytechnic Institute, NY, USA,
∗ IBM, NY, USA
Abstract
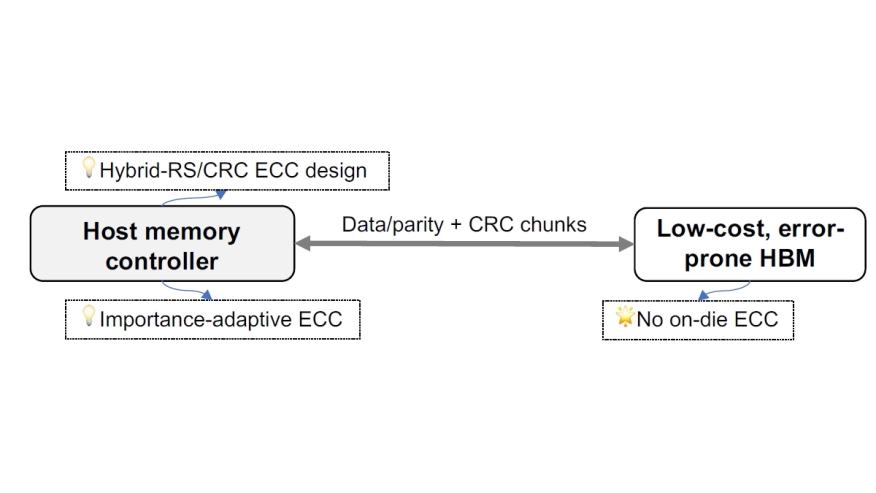
High-Bandwidth Memory (HBM) delivers exceptional bandwidth and energy efficiency for AI workloads, but its high cost per bit, driven in part by stringent on-die reliability requirements, poses a growing barrier to scalable deployment. This work explores a systemlevel approach to cost reduction by eliminating on-die ECC and shifting all fault management to the memory controller. We introduce a domainspecific ECC framework combining large-codeword Reed–Solomon (RS) correction with lightweight fine-grained CRC detection, differential parity updates to mitigate write amplification, and tunable protection based on data importance. Our evaluation using LLM inference workloads shows that, even under raw HBM bit error rates up to 10−3, the system retains over 78% of throughput and 97% of model accuracy compared with systems equipped with ideal error-free HBM. By treating reliability as a tunable system parameter rather than a fixed hardware constraint, our design opens a new path toward low-cost, high-performance HBM deployment in AI infrastructure.
Index Terms — HBM, Error-Correcting Code, CRC, Reliability
To read the full article, click here
Related Semiconductor IP
- HBM Memory Model
- HBM DFI Verification IP
- HBM 4 Verification IP
- HBM Synthesizable Transactor
- HBM DFI Synthesizable Transactor
Related Articles
- Making Strong Error-Correcting Codes Work Effectively for HBM in AI Inference
- TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks
- AIA: A 16nm Multicore SoC for Approximate Inference Acceleration Exploiting Non-normalized Knuth-Yao Sampling and Inter-Core Register Sharing
- Why Software is Critical for AI Inference Accelerators
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding