TensorPool: A 3D-Stacked 8.4TFLOPS/4.3W Many-Core Domain-Specific Processor for AI-Native Radio Access Networks
By Marco Bertuletti 1, Yichao Zhang 1, Diyou Shen 1, Alessandro Vanelli-Coralli 1,2, Frank K. Gürkaynak 1, Luca Benini 1,2
1 Integrated Systems Laboratory (IIS), Eidegenossische Technische Hochschule (ETH), Zurich, Switzerland
2 University of Bologna, Bologna, Italy, and with ETH
Abstract
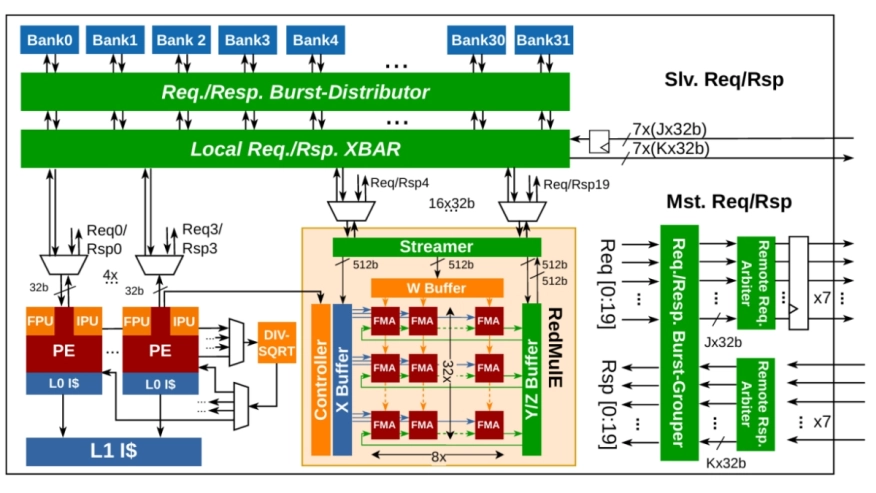
The upcoming integration of AI in the physical layer (PHY) of 6G radio access networks (RAN) will enable a higher quality of service in challenging transmission scenarios. However, deeply optimized AI-Native PHY models impose higher computational complexity compared to conventional baseband, challenging deployment under the sub-msec real-time constraints typical of modern PHYs. Additionally, following the extension to terahertz carriers, the upcoming densification of 6G cell-sites further limits the power consumption of base stations, constraining the budget available for compute (≤ 100 W). The desired flexibility to ensure long term sustainability and the imperative energy efficiency gains on the high-throughput tensor computations dominating AI-Native PHYs can be achieved by domain-specialization of many-core programmable baseband processors. Following the domain-specialization strategy, we present TensorPool, a cluster of 256 RISCV32IMAF programmable cores, accelerated by 16 256 MACs/cycle (FP16) tensor engines with low-latency access to 4MiB of L1 scratchpad for maximal data-reuse. Implemented in TSMC’s N7, TensorPool achieves 3643 MACs/cycle (89% tensor unit utilization) on tensor operations for AI-RAN, 6× more than a core-only cluster without tensor acceleration, while simultaneously improving GOPS/W/mm2 efficiency by 9.1×. Further, we show that 3D-stacking the computing blocks of TensorPool to better unfold the tensor engines to L1-memory routing provides 2.32× footprint improvement with no frequency degradation, compared to a 2D implementation.
Index Terms — 6G, AI, RAN, many-core, RISC-V
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- Physical Design Exploration of a Wire-Friendly Domain-Specific Processor for Angstrom-Era Nodes
- A Direct Memory Access Controller (DMAC) for Irregular Data Transfers on RISC-V Linux Systems
- MultiVic: A Time-Predictable RISC-V Multi-Core Processor Optimized for Neural Network Inference
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding