FeNN-DMA: A RISC-V SoC for SNN acceleration
By Zainab Aizaz, James C. Knight, and Thomas Nowotny
School of Engineering and Informatics, University of Sussex, Brighton, UK
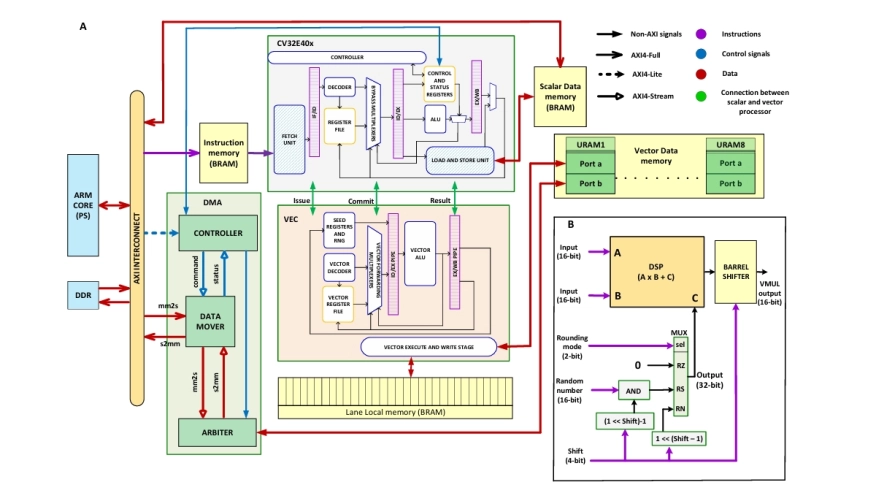
Abstract
Spiking Neural Networks (SNNs) are a promising, energy-efficient alternative to standard Artificial Neural Networks (ANNs) and are particularly well-suited to spatio-temporal tasks such as keyword spotting and video classification. However, SNNs have a much lower arithmetic intensity than ANNs and are therefore not well-matched to standard accelerators like GPUs and TPUs. Field Programmable Gate Arrays (FPGAs) are designed for such memory-bound workloads and here we develop a novel, fully-programmable RISC-V-based system-on-chip (FeNN-DMA), tailored to simulating SNNs on modern UltraScale+ FPGAs. We show that FeNN-DMA has comparable resource usage and energy requirements to state-of-the-art fixed-function SNN accelerators, yet it is capable of simulating much larger and more complex models. Using this functionality, we demonstrate state-of-the-art classification accuracy on the Spiking Heidelberg Digits and Neuromorphic MNIST tasks.
Index Terms—Spiking Neural Networks (SNN), Field Programmable Gate Array (FPGA), RISC-V, Vector processor.
To read the full article, click here
Related Semiconductor IP
- RISC-V Debug & Trace IP
- RISC-V IOPMP IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Multi-core capable RISC-V processor with vector extensions
Related Articles
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- VMXDOTP: A RISC-V Vector ISA Extension for Efficient Microscaling (MX) Format Acceleration
- An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
- AIA: A 16nm Multicore SoC for Approximate Inference Acceleration Exploiting Non-normalized Knuth-Yao Sampling and Inter-Core Register Sharing
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding