An FPGA-Based SoC Architecture with a RISC-V Controller for Energy-Efficient Temporal-Coding Spiking Neural Networks
By Mohammad Javad Sekonji 1, Ali Mahani 1, Maryam Mirsadeghi 1, and Mahdi Taheri 2,3
1 Shahid Bahonar University of Kerman, Kerman, Iran
2 Brandenburg Technical University, Cottbus, Germany
3 Tallinn University of Technology, Tallinn, Estonia
Abstract
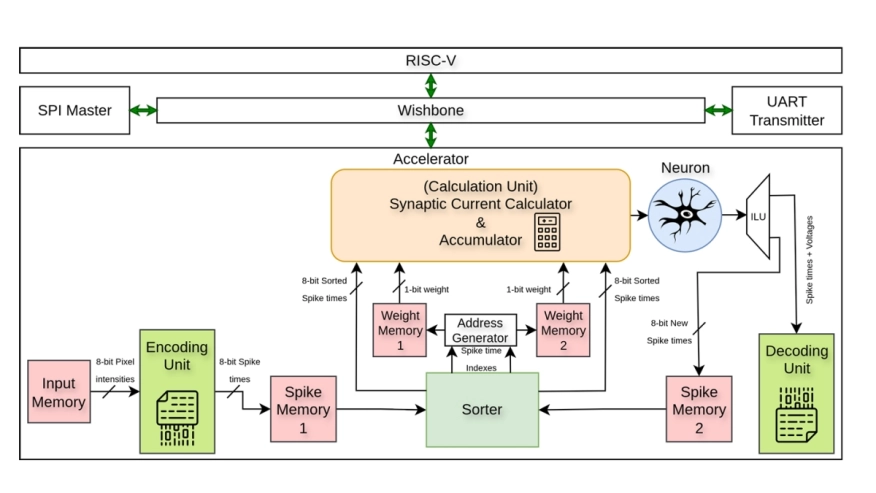
Spiking Neural Networks (SNNs) offer high energy efficiency and event-driven computation, ideal for low-power edge AI. Their hardware implementation on FPGAs, however, faces challenges due to heavy computation, large memory use, and limited flexibility. This paper proposes a compact System-on-Chip (SoC) architecture for temporal-coding SNNs, integrating a RISC-V controller with an event-driven SNN core. It replaces multipliers with bitwise operations using binarized weights, includes a spike-time sorter for active spikes, and skips noninformative events to reduce computation. The architecture runs fully on a Xilinx Artix-7 FPGA, achieving up to 16x memory reduction for weights and lowering computational overhead and latency, with 97.0% accuracy on MNIST and 88.3% on FashionMNIST. This self-contained design provides an efficient, scalable platform for real-time neuromorphic inference at the edge.
To read the full article, click here
Related Semiconductor IP
- RISC-V Debug & Trace IP
- RISC-V IOPMP IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Multi-core capable RISC-V processor with vector extensions
Related Articles
- SNAP-V: A RISC-V SoC with Configurable Neuromorphic Acceleration for Small-Scale Spiking Neural Networks
- Input-Triggered Hardware Trojan Attack on Spiking Neural Networks
- AceleradorSNN: A Neuromorphic Cognitive System Integrating Spiking Neural Networks and Dynamic Image Signal Processing on FPGA
- Store-and-Forward Fat-Tree Architecture for on-Chip Networks
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding