Enabling RISC-V Vector Code Generation in MLIR through Custom xDSL Lowerings
By Jie Lei 1, Héctor Martínez 2, Adrián Castelló 1
1 Universitat Politècnica de València, València, Spain
2 Universidad de Córdoba, Córdoba, Spain
Abstract
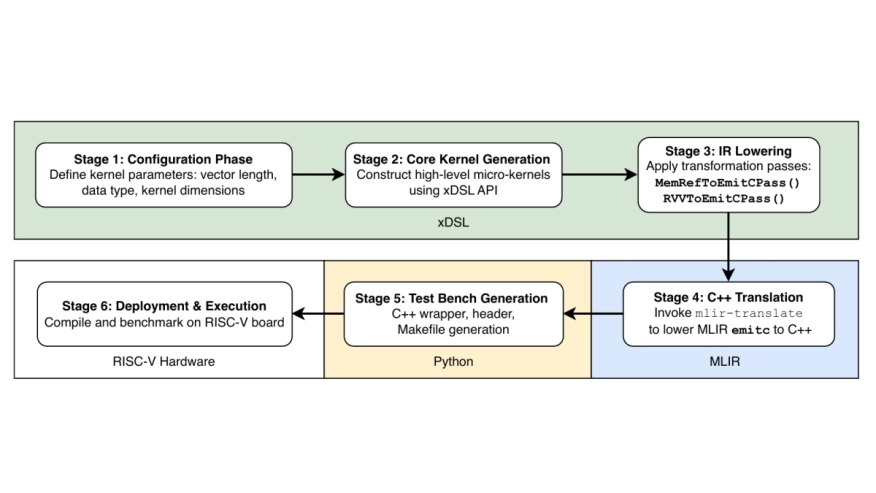
The growing adoption of RISC-V in high-performance and scientific computing has increased the need for performance-portable code targeting the RISC-V Vector (RVV) extension. However, current compiler infrastructures provide limited end-to-end support for generating optimized RVV code from high-level representations to low-level implementations. In particular, existing MLIR distributions lack practical lowering paths that map high-level abstractions to RVV intrinsics, limiting their applicability for production-ready RISC-V kernels. This paper presents a compilation approach that combines MLIR with xDSL to bridge the missing lowering stages required for RVV code generation. Using custom intermediate representations and transformation passes implemented in xDSL, we systematically translate high-level operations into specialized, hardware-aware C code invoking RVV intrinsics. The resulting kernels are emitted as portable C functions that can be directly integrated into existing applications, enabling incremental adoption without modifying surrounding software stacks. We demonstrate the approach on the General Matrix Multiplication (GEMM) kernel and evaluate the generated micro-kernels on two real RISC-V platforms, the K230 and the BananaPi F3, comparing against OpenBLAS for both square-matrix benchmarks and transformer-based workloads derived from the BERT-Large model. When integrated into a matrix multiplication kernel, the proposed approach consistently outperforms OpenBLAS, reaching up to 12.2 GFLOPS compared to the baseline's 5.1 GFLOPS and providing performance improvements between 10--35\% across the evaluated workloads. These results demonstrate that combining MLIR with xDSL provides a practical pathway to portable, optimized code generation for RISC-V platforms.
To read the full article, click here
Related Semiconductor IP
- RISC-V Debug & Trace IP
- RISC-V IOPMP IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Multi-core capable RISC-V processor with vector extensions
Related Articles
- Automatically Retargeting Hardware and Code Generation for RISC-V Custom Instructions
- Case study: optimizing PPA with RISC-V custom extensions in TWS earbuds
- CircuitGuard: Mitigating LLM Memorization in RTL Code Generation Against IP Leakage
- Closer in the Gap: Towards Portable Performance on RISC-V Vector Processors
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding