CRADLE: Conversational RTL Design Space Exploration with LLM-based Multi-Agent Systems
By Lukas Krupp, Maximilian Schoffel, Elias Biehl, and Norbert Wehn ¨
RPTU University of Kaiserslautern-Landau, Kaiserslautern, Germany
Abstract
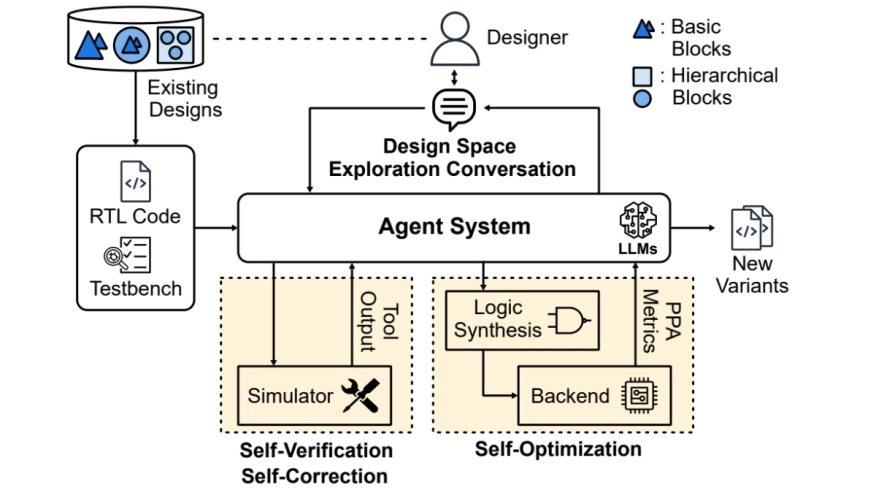
This paper presents CRADLE, a conversational framework for design space exploration of RTL designs using LLM-based multi-agent systems. Unlike existing rigid approaches, CRADLE enables user-guided flows with internal selfverification, correction, and optimization. We demonstrate the framework with a generator-critic agent system targeting FPGA resource minimization using state-of-the-art LLMs. Experimental results on the RTLLM benchmark show that CRADLE achieves significant reductions in resource usage with averages of 48% and 40% in LUTs and FFs across all benchmark designs.
Index Terms—LLM, Agents, Design Space Exploration, RTL
To read the full article, click here
Related Semiconductor IP
- Adaptive Voltage Scaling (AVS) Bus Target IP
- Adaptive Voltage Scaling (AVS) Bus Host Controller
- NoC Interconnect IP Generator
- Over-Voltage Lockout (OVLO) IP
- Verification IP for Universal Chiplet Interconnect Express (UCIe) up to 3.0
Related Articles
- Veri-Sure: A Contract-Aware Multi-Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation
- Simultaneous Exploration of Power, Physical Design and Architectural Performance Dimensions of the SoC Design Space using SEAS
- Simultaneous Exploration of Power, Physical Design and Architectural Performance Dimensions of the SoC Design Space using SEAS
- Configure, Confirm, Ship: Build Secure Processor-Based Systems with Faster Time-to-Market
Latest Articles
- Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
- Si-GT: Fast Interconnect Signal Integrity Analysis For Integrated Circuit Design Via Graph Transformers
- Hardware Mechanisms to Dynamically Throttle AI Performance
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers