AutoGNN: End-to-End Hardware-Driven Graph Preprocessing for Enhanced GNN Performance
By Seungkwan Kang 1, Seungjun Lee 1, Donghyun Gouk 2, Miryeong Kwon 2, Hyunkyu Choi 2, Junhyeok Jang 2, Sangwon Lee 2, Huiwon Choi 1, Jie Zhang 3, Wonil Choi 4, Mahmut Taylan Kandemir 5, Myoungsoo Jung 1,2
1 Computer Architecture and Memory Systems Laboratory, KAIST,
2 Panmnesia, Inc.,
3 Peking University,
4 Hanyang University,
5 Pennsylvania State University
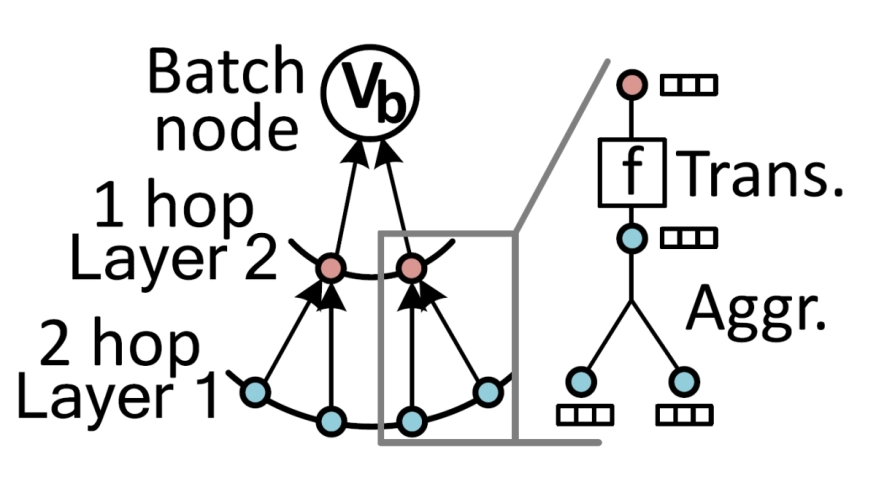
Abstract
Graph neural network (GNN) inference faces significant bottlenecks in preprocessing, which often dominate overall inference latency. We introduce AutoGNN, an FPGA-based accelerator designed to address these challenges by leveraging FPGA’s reconfigurability and specialized components. AutoGNN adapts to diverse graph inputs, efficiently performing computationally intensive tasks such as graph conversion and sampling. By utilizing components like adder trees, AutoGNN executes reduction operations in constant time, overcoming the limitations of serialization and synchronization on GPUs.
AutoGNN integrates unified processing elements (UPEs) and single-cycle reducers (SCRs) to streamline GNN preprocessing. UPEs enable scalable parallel processing for edge sorting and unique vertex selection, while SCRs efficiently handle sequential tasks such as pointer array construction and subgraph reindexing. A user-level software framework dynamically profiles graph inputs, determines optimal configurations, and reprograms AutoGNN to handle varying workloads. Implemented on a 7nm enterprise FPGA, AutoGNN achieves up to 9.0× and 2.1× speedup compared to conventional and GPU-accelerated preprocessing systems, respectively, enabling high-performance GNN preprocessing across diverse datasets.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- Boosting RISC-V SoC performance for AI and ML applications
- CANDoSA: A Hardware Performance Counter-Based Intrusion Detection System for DoS Attacks on Automotive CAN bus
- Modeling and Optimizing Performance Bottlenecks for Neuromorphic Accelerators
- ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding