ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
By Zhongkai Yu 1, Chenyang Zhou 2, Yichen Lin 1, Hejia Zhang 1, Haotian Ye 1, Junxia Cui 1, Zaifeng Pan 1, Jishen Zhao 1, Yufei Ding 1
1 Department of Computer Science and Engineering, University of California San Diego, La Jolla, US
2 Columbia University, New York, US.
Abstract
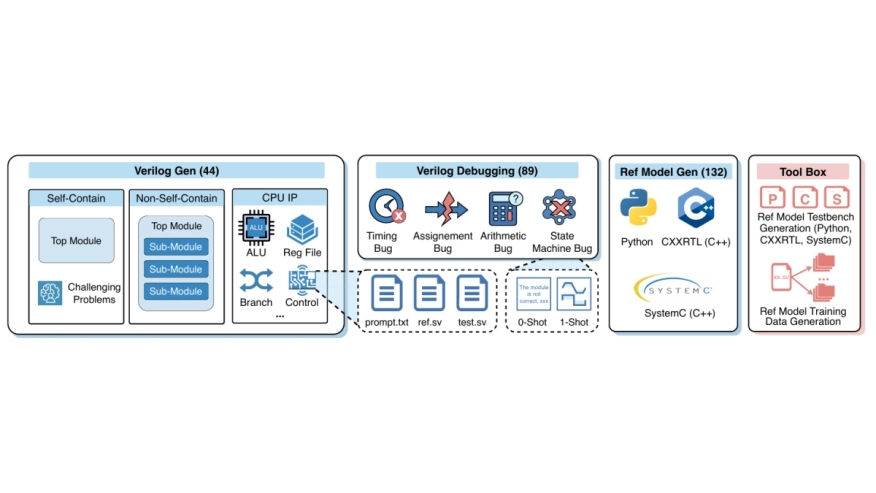
While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs’ performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical struc tures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the art Claude-4.5-opus achieving only 30.74% on Verilog generation and 13.33% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95% pass rates. Additionally, to help enhance LLMreference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- TTP: A Hardware-Efficient Design for Precise Prefetching in Ray Tracing
- Integrating VESA DSC and MIPI DSI in a System-on-Chip (SoC): Addressing Design Challenges and Leveraging Arasan IP Portfolio
- It's Just a Jump to the Left, Right? Shift Left in IC Design Enablement
- Why Interlaken is a great choice for architecting chip to chip communications in AI chips
Latest Articles
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding
- Vectorizing Quantum Control: A RISC-V Vector Extension Architecture for Scalable Qubit Systems