A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
By Fang-Chi Chang, and Tian-Sheuan Chang
Institute of Electronics, National Yang Ming Chiao Tung University, Taiwan
Abstract
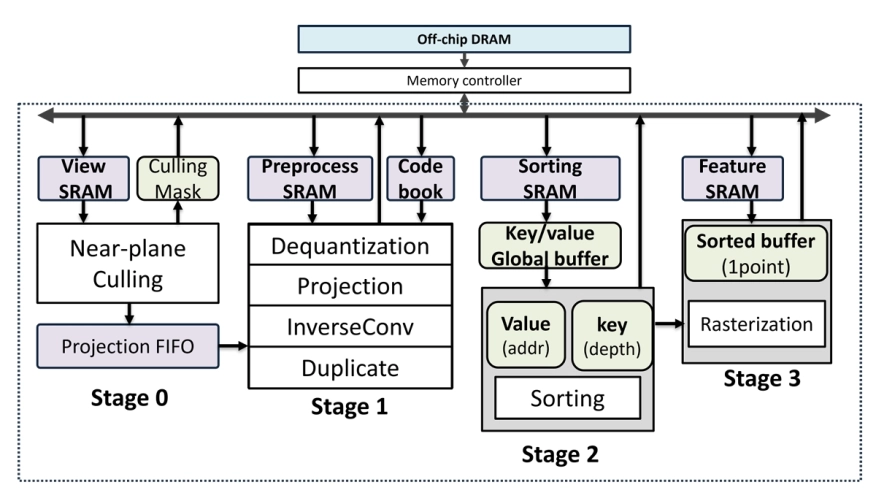
Rendering large-scale, unbounded scenes on AR/VR-class devices is constrained by the computation, bandwidth, and storage cost of 3D Gaussian Splatting (3DGS). We propose a low-power, low-cost 3DGS hardware accelerator that renders full-HD images in real time, together with a hardware-friendly compression pipeline that combines iterative Gaussian pruning and fine-tuning, progressive spherical harmonics (SH) degree reduction, and vector quantization of all SH coefficients and colors. The scheme achieves a 51.6× model-size reduction with a 0.743 dB PSNR loss. The accelerator uses a frame-level pipeline that integrates point-based culling and projection with tile-based sorting and rasterization, skips zero-Jacobian matrix multiplications (reducing processing elements by 63\% and computation by 53\%), and adopts comparison-free tile-based sorting with deterministic latency. Implemented in a TSMC 28-nm process at 800 MHz, the design occupies 0.66 mm2 with 1.1438 M gates and 120 kB SRAM, consumes 0.219 W, and delivers 1219 Mpixels/J at 267.5 Mpixels/s, enabling 1080p at 129 FPS. Overall, it is 5.98× smaller in area, 5.94× higher throughput, and delivers 7.5× higher energy efficiency than prior 3DGS accelerators.
Index Terms—3D Gaussian Splatting, hardware accelerators, model compression, real-time rendering
To read the full article, click here
Related Semiconductor IP
- 64-bit, RISC-V, ultra-high performance processors
- 64-bit, RISC-V, performance and data computation processors
- 32-bit, RISC-V, deeply embedded processors
- Verification IP for eUSB 2 v2 and USB 2.0
- AFDX 1G Switch IP
Related Articles
- Vorion: A RISC-V GPU with Hardware-Accelerated 3D Gaussian Rendering and Training
- A 16 nm 1.60TOPS/W High Utilization DNN Accelerator with 3D Spatial Data Reuse and Efficient Shared Memory Access
- A Persistent-State Dataflow Accelerator for Memory-Bound Linear Attention Decode on FPGA
- VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
Latest Articles
- Design and Development of a Neuromorphic Silicon Suite: PVT Sensing, Stochastic LIF Inference, On-Chip STDP Learning, and Crossbar Programming
- LLM4RTL: Tool-Assisted LLM for RTL Generation
- Towards Delta Aware Training: Efficient DNN Weight Storage for Resource-Constrained FPGAs
- CHERI-D: Secure and efficient inline object ID for CHERI temporal memory safety
- AIA: A 16nm Multicore SoC for Approximate Inference Acceleration Exploiting Non-normalized Knuth-Yao Sampling and Inter-Core Register Sharing